NxtPost - User To Post Recommendations In Facebook Groups
Created: 2022-06-19 08:37
#paper
Main idea
NxtPost is a user-to-post Content-based filtering Sequential RS for Facebook Groups that uses a Transformer-based model. Causal masked multi-head attention is used to optimize both short and long-term user interests. Recommendable posts can have a corpus of variable length.
Challenges:
- cardinality of posts -> billions of posts are created each day;
- volatility of posts -> short shelf-life, i.e. there is a little overlap between engaged posts week over week;
- many types of engagement across multiple surfaces (likes, reacts, shares, views, clicks , leaving a comment etc)
The learnable token embedding in the Transformer is replaced with a pre-trained item embedding, while the classification layer is removed on behalf of a two tower architecture. Causal attention and two losses are used to optimize both short and long-term user preferences.
In the paper also the developing phase is described, plus how the authors tuned the experiments to reach higher efficiency in online A/B testing.
In deep
Architecture
NxtPost is a two tower/ dual encoder architecture with in-batch negatives. The two-tower model works in the following way:
- the user tower is applied to obtain a user embedding tensor of dimension (B,D), where B is the size of the batch;
- we do the same with the post tower;
- we L2-normalize the embeddings and perform matrix multiplication of the normalized embedding matrices -> as a result we have a matrix of shape (B,B) that represents user-post similarity for every possible pair within a batch (rows are users, columns posts);
- we consider this as a multi-class classification problem, where the number of classes is B and the ground-truth class indices are in the main diagonal -> use multi-class cross-entropy loss to optimize the network.
The number of learnable parameters in a Two Tower model is independent of the number of items/tokens in the vocabulary.
Post/Item embeddings: a post can include text, images, videos and additional metadata. For the textual fields XLM-R encoder is used. A pre-trained model (VisRel) is used on each image and then a shared MLP layer and deep sets fusion are used to combine the set of image embeddings into a fixed size representation. The representations from different feature channels are fused with learned attention weights to get the document's final embedding representation. For video representation video embeddings are got using this method. Once we have the embeddings, the model is trained as a post to post task using a Two Tower architecture, as in this paper. The post embeddings are fed as token embeddings to the Transformer encoder of the user tower.
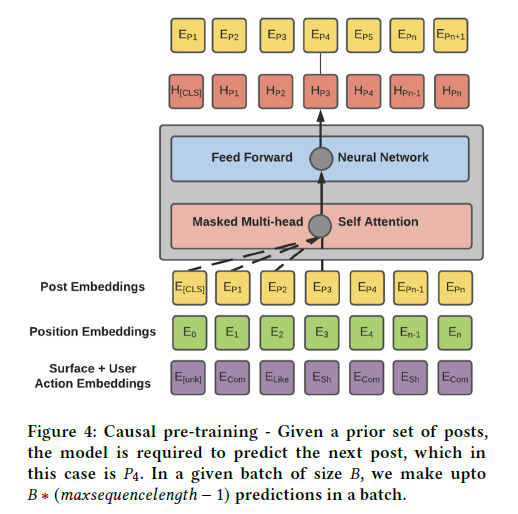
User Tower: a sequence of posts' embeddings is fed to a Transformer encoder layer with causal attention mask. Along with the embeddings, we also concatenate others features like time. Finally, we sum the opst embeddings with learned position embeddings and learned user action embeddings and fed this as input to the transformer layer.
NexPost_Tower.PNG
{kind=link}
Short Term User Interests: the causal masking in the Transformer encoder layer is used to model user's short-term interests, because it avoids peeking into the future -> for every timestamp t, we take the hidden representation of the Transformer encoder layer at time step t and match it with the post embedding at time step (t+1). All the posts that belong to other users are considered as negatives and optimized using a Cross-entropy loss.
Long Term User Interests: to model the user's long term interests, the final hidden representation from the transformer encoder with causal masking is taken and matched with every post embedding at various time steps from (t+1) to (t+m) where m is the maximum number of labels we are considering. Also in this case we use all the labels from other users as negatives and use Cross-entropy loss to optimize the problem. The total loss is the weighted combination of the short term interest loss and the long term interest loss.
Transformer Encoder Layer: it consists in 4 building blocks:
- Embedding layer: traditionally a transformer layer has three embeddings (token, position and segment). Here the position embedding is kept as usual, the token embedding is replaced by an external content based post encoder that is trained on content similarity (two posts are similar if their content are similar) and the segment embedding is replaced by a combination of surface (here?) and user-action embedding (each action has a weight, and then an embedding, that is different). The three embeddings are passed to a transformer encoder layer;
- Multi-Head Attention: used as usual;
- Position Wise Feed Forward Layer: a feed-forward network is applied to each position separately and identically. It consists of two linear layers with ReLU activation between them: $FFN(x)=max(0,xW_1+b_1)W_2+b_2$;
- Pooling layer: this is the final layer which takes a hidden representation at every position, pools them and provides a fixed representation of the entire sequence. Of the several version of pooling, mean pool works best.
Training
User actions and posts are taken from Facebook Groups. The loss uses scaled cosine similarity between a post and a user: $loss_i=-\log(\dfrac{e^{s \cdot cos(u_i,p_i)}}{\sum_{j=1}^{B}e^{s \cdot cos(u_i,p_j)}})$.
Evaluation
Before running A/B tests, the model is evaluated offline using batch Recall@K (also called Hits@K).
Batch Hits@K measures if the diagonal element $cos(q_i,d_i)$ is among the top K scores of the row $cos(q_i,d_j), j \in [1,B]$. Since this measure is easy to compute, it was used to iterate over models ideas.
KNN Hits@K, instead, is more representative but more computationally expensive.
Ablation study
As a baseline a Wide & Deep Learning architecture was used and the model described in this paper (two tower + modelling of user's long-term interests) obtained +49% improvements in metrics. In particular modelling long-term interests increases the performances of the model consistently (probably because by just considering a short amount of time, the short term interests may be biased towards a set of particular topics).
Studies on the length for the context sequence were done.
To capture user behavior, the authors added the relative time of engagement and noted the following:
- the model gives less preferences to older engagement regardless of the position in the history;
- the model pays more attention to posts where user signaled more long term interest such that visiting the group and consuming posts across multiple user sessions.
About the number of negatives, since the short-term interests' problem is modeled as a multi-label multi-class problem, for a certain user we can have upto N positives (where N is the maximum sequence length in the Transformer) and all the posts from other users as considered as negative.
To deal with Cold-start and marginal users (i.e. users with just few interactions), several approaches were used:
- backfilling user engagement with popular posts
- using personalized model to backfill engagement from other similar users -> use a user-user similarity model based on engagement and backfill the history of marginal users from other similar users.
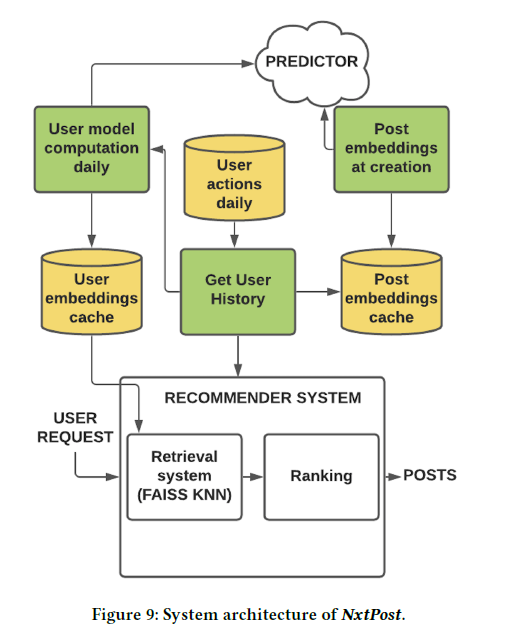
System Architecture
NextPost_architecture.PNG
Model inferences are computed in a cloud service called Predictor.
Upon the creation and update of a post, an asynchronous call will be made to Predictor to generate its post embedding and the recommendations index is updated and prepared so that the post can be retrieved and ranked.
{kind=link}
User embeddings are re-computed daily.
To compress and retrieve efficiently the embeddings, FAISS library is used.
To guarantee that the RS stays engaged, the system efficiency is measured by click-through rate (CTR), that needs to stay constant (or improve) over time.