Wide & Deep Learning
Created: 2022-03-24 12:20
#paper
Main idea
By using joyntly a linear and a neural components this model achieves both memorisation and generalisation.
In deep
A goal in recommendation systems is to achieve both memorization and generalization.
Memorisation can be defined as the capacity of the system to learn the frequent co-occurrence of items or features and exploiting the correlation available in the historical data. Systems based on memorization are usually more topical and generally more tied to the user's history, so they are not very good for data that did not happear in the training data.
Generalisation is based on the transitivity of correlation and explores new feature combinations that have never or rarely occurred in the past. Such system can improve the diversity of the recommended items but the could omit less relevant items.
The Wide & Deep model achieve both memorisation and generalisation by jointly training a linear component and a neural component as shown in
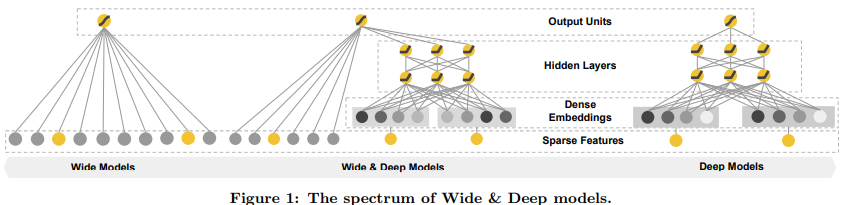
- The wide component: it is simply a linear model of the form $$y = w^Tx+b$$. The feature set includes raw input features and transformed ones. One important transformation is the cross-product transformation, defined as $\phi_k(x)$ $= \sum_{i=1}^d x_{i}^{c_{k_i}} \hspace{1em} c_{k_i} \in {0,1}$;
- The deep component is a feed-forward neural network. Categorical features are converted nito low-dimensional and dense vectors, the embedding vectors. These vectors are then fed to the hiddenlayers of a neutal network in the forward pass. Each hidden layer performs this operation: $a^{l+1}=f(W^{l}a^{l}+b{l})$ where l is the layer number and f is the activation function (generally ReLU).
The two components are combined using a weighted sum of their output log odds and then the result is fed to one common logistic loss function.
Note: this is a joint training, not an ensemble, this means that the models' parameters are leaned and optimized together.
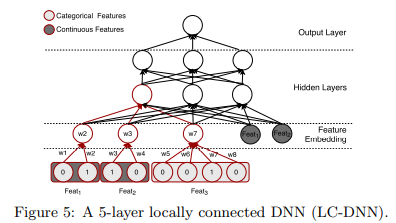
In this work, it is proposed a general locally connected deep learning framework (LC-DNN) to address large-scale industrial-level recommendation task, that transforms the one-hot sparse features into dense input and significantly reduces the model size.
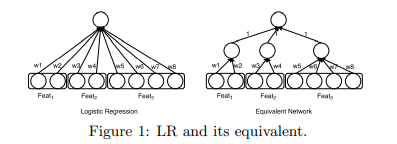
The main idea behind this paper is that we can decompose the weight matrix W into two smaller matrixes $M_1$ and $M_2$, where the first matrix can be pre-trained by the logistic regression method (or to be more precise its equivalent 3-layer model, as shown in the following image).
References
- Medium on W&D
- Wide & Deep
- Locally Connected Deep Learning Framework for Industrial-scale Recommender Systems
- Youtube recommendation
Tags
#wide_deep_learning