CoSeRNN
Created: 2022-06-24 09:30
#paper
Main idea
In music recommendations that are several challenges that are different to the ones we can encounter in other fields -> tracks are short, listened to multiple times, tipically consumed in sessions with other tracks and relevance is highly context-dependent.
A way to deal with this aspects is presented in this paper -> modeling users' preferences at the beginning of a session, considering past consumptions and session-level context (like time of the day or the device used to access the service).
The starting point is a vector-space embedding of tracks, where two tracks are close in space if they are likely to be listened to successively. A user is modeled as a sequence of context-dependent embeddings, one for each session. A variant of a RNN is trained to maximize the cosine similarity between its output and the tracks played during the session, given the current session context and the representation of the user's past consumption.
So, his models learns user and item embeddings separately not jointly like most of other models -> this can help in improving the modularity of the model, since we could change or add components.
Recap: this model does not predict the individual tracks inside a sesion; instead it generates a session-level user embedding and relies on the fact that tracks will lie inside a small region of the space. Furthermore, representing a session as an embedding overcome the fact that predict every individual item in a session becomes intractable.
The model takes inspiration from the approach of JODIE, described in JODIE-Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks.
In deep
Session-level information
Information collected is about:
- the set of tracks played during the session;
- which tracks were skipped;
- the stream source (user playlist, top charts etc);
- a timestamp representing the start of the session;
- the device used to access the service
Notation:
- $D_t$ -> Day of the week;
- $H_t$ -> Time of the day;
- $Y_t$ -> device;
- $N_t$ -> number of tracks in session;
- $\Delta_t$ -> time since last session;
- $z_t$ -> stream source;
- $s_t$ -> session embedding, all tracks;
- $s_t^+$ -> session embedding, played only;
- $s_t^-$ -> session embedding, skipped only
The session embeddings are 40-dimensional.
Embeddings
Tracks are embeddded using word2vec on a set of user-generated playlists.
A session is represented as an average of the embedding of the tracks it contains -> it is a summary of the session's content.
It is needed to say that for long sessions it is not clear if context stays constant throught its duration -> the authors keep just the first 10 tracks, i.e. they are predicting just the beginning of the session.
Architecture
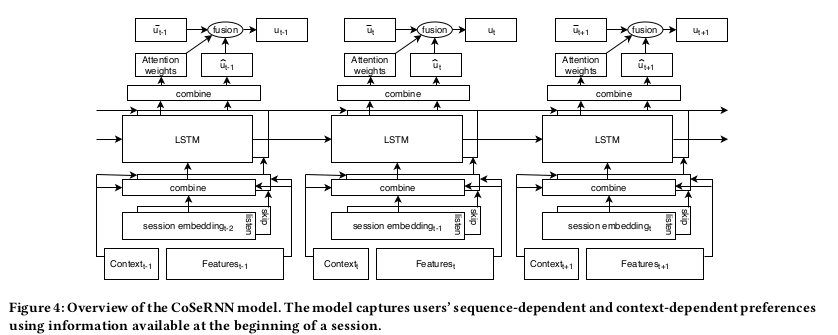
For the session with index t, the predicted session-level user embedding is defined as $u_t \in R^{40}$ and the observed session embeddings as $s_t^-, s_t^+ \in R^{40}$. The model has to maximize the similarity between $u_t$ and $s_t^+$.
CoSeRNN uses features from the current context and features about the last session as input to two RNNs, representing play and skip behavior. The RNNs combine the input with a latent state to capture user's consumption habits. The outputs of the two RNNs are then combined and fused with a long-term user embedding.
Input layers: the two features vectors are defined as follows: $f_t^+=c_T \oplus s_{t-1}^+ \oplus \begin{bmatrix}N_{t-1} & z_{t-1} & \Delta_t\end{bmatrix}$ and $f_t^-=c_T \oplus s_{t-1}^- \oplus \begin{bmatrix}N_{t-1} & z_{t-1} & \Delta_t\end{bmatrix}$, where $c_t$ is a concatenation of one-hot encodings of the contextual variables $D_t$, $H_t$ and $Y_t$ ($\oplus$ stands for concatenation). Prior to passing the features to the RNN, we apply a learned nonlinear transformation to help the RNN to better focus on modeling latent sequential dynamics. The transformation is $\hat{f_t^+}=FC_{ReLU}\circ FC_{ReLU}(f_t^+)$ (same for $\hat{f_t^-}$).
The RNNs are LSTM models and are defined as: $(o_t^+, h_t^+)=LSTM(\hat{f_t^+}|o_{t-1}^+,h_{t-1})$ where $o_t^+$ is the output and $h_t^+$ is the hidden state.
To combine the outputs of the two RNNs we do: $o_t=FC_{ReLU} \circ FC_{ReLU}(o_t^- \oplus o_t^+)$ and the we can get the user embedding as $\hat{u_t}=FC_{id}(o_t)$.
Long-term user embedding is defined as a weighted average of all the previous session embeddings: $\bar{u_t} \propto \sum_{t'=1}^{t-1} \dfrac{t'}{t-1}s_{t'}$ normalized such that $|\bar{u_t}|=1$. To fuse $\bar{u_t}$ and $\hat{u_t}$ the authors used attention weights based on the RNN output. The final user embedding is produced as $u_t=\hat{\beta_t}\hat{u_t}+\bar{\beta_t}\bar{u_t}$ where $\begin{bmatrix}\hat{\beta_t} & \bar{\beta_t}\end{bmatrix}=FC_{softmax}(o_t)$.
Loss function
The model is trained to maximize the similarity between the predicted embedding $u_t$ and the observed one $s_t$.
Given the training set D composed of pairs (i,t) where i is the user and t the session, the loss function is defined as $l= \sum_{(i,t) \in D}(1-u_{it}^Ts_{it}^+)$ where $u_{it}$ and $s_{it}^+$ refer to the t-th session of user i. The loss is minimized using stochastic gradient descent with mini-batches and Adam optimizer.