JODIE-Predicting Dynamic Embedding Trajectory In Temporal Interaction Networks
Created: 2022-06-29 09:29
#paper
Main idea
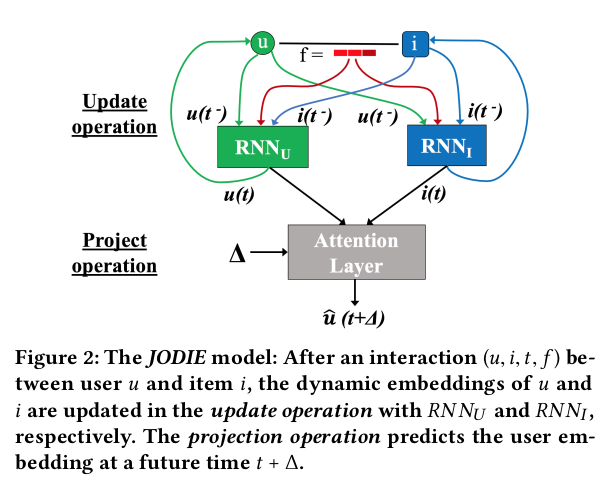
JODIE is a coupled recurrent neural network model that learns the embedding trajectories of users and items. The embeddings of the user and the item are updated when a user takes an action and a projection operator predicts the future embedding trajectory of the user.
Each user and item has a static embedding (long-term preferences) and a dynamic one (short-term preferences). Both are used to generate predictions.
The two major components are:
- the update operation -> it is composed of two RNNs to generate user and item embeddings. After each iteration, the user RNN updates the user embeddings by using the embedding of the interacting item (and viceversa, the item RNN uses the user embedding to update the item embedding). Feature vectors from the interactions can be included;
- the projection operation -> it predicts the future embedding trajectory of the users. A temporal attention layer is used to project the embeddings of users after some time $\Delta$ after its previous interaction.
Instead of producing as output an interaction probability between a user and all the items, by directly generating the item embedding, we can recommend the item that is closest to the predicted item in the embedding space (using LSH for example).
Another key aspect of this model is the batching algorithm, t-Batch, which creates batches of independent interactions such that the interactions en each batch can be processed in parallel. This makes training much faster.
The most similar SOTA algorithm is DeepCoevolve but JODIE uses a projection operation and t-batch for training. These addictions lead to an improvement of 9.2x in training time, 45% in predicting future interactions and 13.9% in predicting user state change on average.
In deep
Users are defined as $u(t) \in R^n, \forall u \in U$ and items as $i(t) \in R^n, \forall i \in I$, $\forall t \in [0,T]$ from an ordered sequence of temporal user-item interactions $S_r=(u_r,i_r,t_r,f_r)$. An interaction $S_r$ happens between a user $u_r \in U$ and item $i_r \in I$ at time $t_r \in R^+, 0 < t_1 \leq t_2 \leq ... \leq T$. $f_r$ is the featuer vector associated to the interaction.

For static embeddings, one-hot vectors are used.
Embedding update operation
Updates are computed using two RNNs, $RNN_U$ updates user embeddings while $RNN_I$ updates item embeddings.
The two RNNs are mutually-recursive, i.e. when user u interacts with the item i, $RNN_U$ updates the embedding u(t) by using the embedding $i(t^-)$ of item i right before time t as input.
By using the item's embedding instead of the one-hot vector, the authors claim to get more meaningful dynamic user embeddings and easier training (and the one-hot vector can become huge). $RNN_I$ updates the dynamic embedding i(t) of item i by using the dynamic user embedding $u(t^-)$, i.e. it uses u's embedding right before time t. More formally:
$u(t)= \sigma(W^u_1 u(t^-)+W^u_2 i(t^-) +W^u_3 f +W^u_4 \Delta_u)$
$i(t)=\sigma(W^i_1 i(t^-) + W^i_2 u(t^-) + W^i_3 f + W^i_4 \Delta_i)$
where $\Delta$ denotes the time since u's previous interaction (with any item) and $\Delta_i$ is the time since item i's previous interaction (with any user); f is the interaction feature vector. The matrices $W^u_1,...,W^u_4$ are the parameters of $RNN_U$ nd matrices $W^i_1,...,W^i_4$ are the parameters of $RNN_I$.
LSTM, GRU and T-LSTM were also tried, but gave worse results.
Embedding projection operation
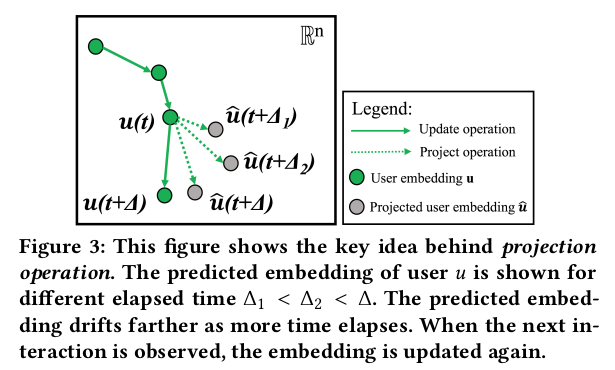
This operation projects the embedding of a user after some time has elapsed since its last interaction at time t.
Two inputs are needed: u's embedding at time t and the elapsed time $\Delta$.
To incorporate time into the projected embedding Hadamard product and this paper are considered. $\Delta$ is converted to a time-context vecotr $w \in R^n$ using a linear layer (represented by vector $W_p$): $w=W_p\Delta$. $W_p$ is initialized by a 0-mean Gaussian. The project embedding is then obtained as an element-wise product of the time-context vector with the previous emedding as follows: $\hat u(t+\Delta)=(1+w)\cdot u(t)$, where $1+w$ acts as a temporal vector to scale the past user embedding.
Non linear transformation gave worse results than a simple linear one.
Training
JODIE is trained to minimize the $L_2$ difference between the predicted item embedding $\tilde j(t+\Delta)$ and the real item embedding $[\bar j,j(t+\Delta^-)]$ as follows: $|| \tilde j(t+\Delta)-[\bar j,j(t+\Delta^-)]||_2$, where $[x,y]$ is the concatenation of x and y, and $\bar j$ is the embedding of j immediately before the time.
$\tilde j(t+\Delta)$ is computed as follows: $\tilde j(t+\Delta)=W_1 \hat u(t+\Delta)+W_2 \bar u +W_3 i(t+\Delta^-) +W_4 \bar i +B$, where $i(t+\Delta^-)$ is considered because item i could have iteracted with other users between time t and $t+ \Delta$ and users often interact with the same item consecutively.
The total loss is computed as follows: $Loss = \sum_{(u,i,t,f) \in S} ||\tilde j(t)-[\bar i, i(t^-)]||_2 + \lambda_U||u(t)-u(t^-)||_2 + \lambda_I||i(t)-i(t^-)||_2$. The first term minimizes the predicted embedding error, the last two are added to regularize the loss and prevent the consecutive dynamic embeddings of a user and itme to vary too much, respectively. $\lambda_U$ and $\lambda_I$ are scaling parameters to ensure the losses are in the same range.
t-Batch
As already said, t-batch is used to parallelize the training of JODIE. It is important to maintain temporal dependencies between interactions during training -> $\forall r < k$, $S_r$ is processed before $S_k$.
Given the fact that in JODIE there are two mutually-recursive RNNs, it is impossible to simply split users into separate batches and processing them in parallel. A solution consists in creating each batch by selecting independent edge sets of the interaction network, i.e. two interactions in the same batch do not share any common user or item. To do so, we need to iterate over two steps (until no edges remain in the graph):
- select step -> a new bacth is created by selecting the maximal edge set such that each edge (u,i) is the lowest timestamped edge incident on both u and i. A batch obtained in this way is an independent edge set;
- reduce step -> the edges selected in the previous step are rempved from the network.
In practice, the algorithm assigns each interaction $S_r$ to a batch $B_k$ where $k \in [1, |I|]$ (we initialize $|I|$ batches for the worst scenario, i.e. each batch has one interaction). We iterate through the temporally-sorted sequence of interactions $S_1,...,S_{|I|}$ and add each interaction to a batch $B_k$. The interaction $S_{r+1}$ between user u and item i is assigned to the batch with $index = max(1+maxBatch(u,r), 1+maxBatch(i,r))$ where maxBatch(e,r) is the batch with the largest index that has an interaction involving an entity e till interaction $S_r$.
The complexity of such algorithm is $O(|S|)$.
Experiments
The tasks considered are: future interaction prediction and user state change prediction (predicting if a user will be banned and predicting if a student will drop-out of a course).
Experiments were conducted on three datasets each and comparison with six strong baselines were done.
More details in the paper.
For the first task, JODIE outperforms all baselines by at least 20% in MRR and 14% in recall@10; in the second task, JODIE outperforms the baselines by at least 12.63% on average.
Training time are comparable to the other methods (and much faster compare to DeepCoevolve) thanks to t-Batch (without using it, trainings result 8.4x slower).