Serving ML Models
Created: 2023-03-02 10:59
#quicknote
There are several optiont to format an ML model:
- serializing the model with pickle;
- MLFlow provides a serialization format;
- language-agnostic exchange format (ONNX, PMML etc).
To check the requirements, the challenges, and the pipelines to serve ML models, check Model Deployment and Challenges for ML Deployment.
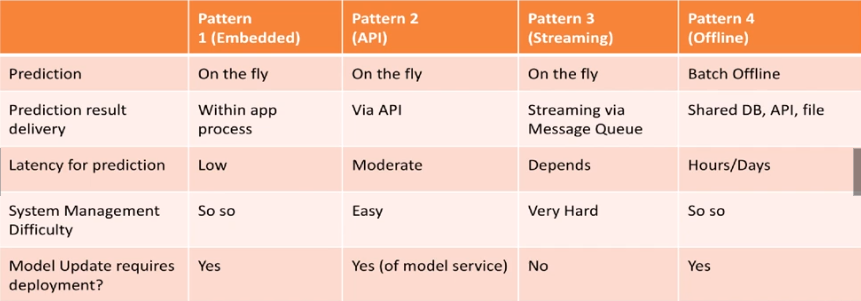
There are various architecture we can consider when deploying an ML model:
- Embedded approach: a trained model is embedded as a dependency in the application. Simplicity instead of flexibility;
- Dedicated Model API: the model is external to the application and is called through an API (REST, gRPC etc). The tradeoff is inverted, i.e. flexibility is elevated but system is more complex;
- Model published as Data (Streaming): applications subscribe to events and ingest new models in memory. It uses asynchronous calls to queues;
- Offline predictions (Batch): asynchronous, prediction-on-the-fly is not available but we can check the predictions before serving them to the users.
For operational considerations related to these architectures, see Scaling model serving.
Resources
Tags
#mlops #deployment #course