Approximate Nearest Neighbour
Created: 2022-08-23 14:56
#note
To search for nearest neighbours we could use two approacehs:
- Exhaustive search -> comparing each point to every other point;
- Grid trick -> subdiving the space into a Grid
The grid trick requires exponential time/space, so it is unfeasible for high dimensional data, while exhaustive search is linear (in the size of the dataset).
However, sometimes, the linearity of our algorithm can be a problem if the data is too massive -> we can use Approximate nearest neighbours (ANN) which will significantly improve the performance of the retrieval, by trading a bit in accuracy.
The way ANN reaches this is by preprocessing the data into an efficient index, generally using these three phases:
- Vector transformation: applied on vectors, it consists in operations like dimensionality reduction or vector rotation;
- Vector encoding: applied to vector to actually build the index, it consists in structure-based techniwues like Trees, LSH and Quantization;
- None exhausting search component: applied on vectors in order to avoid exhaustive search, it consists in techniques like Inverted Files and Neighborhood Graphs.
Evaluating which algorithms should be used and when depends on the use case and can be affected by these metrics:
- Speed- Index creation and Index construction.
- Hardware and Resources- Disk size, RAM size, and whether we have GPU.
- Accuracy Requirements.
- Access Patterns — Number of queries, batch or not, and whether we should update the index.
Famous libraries are:
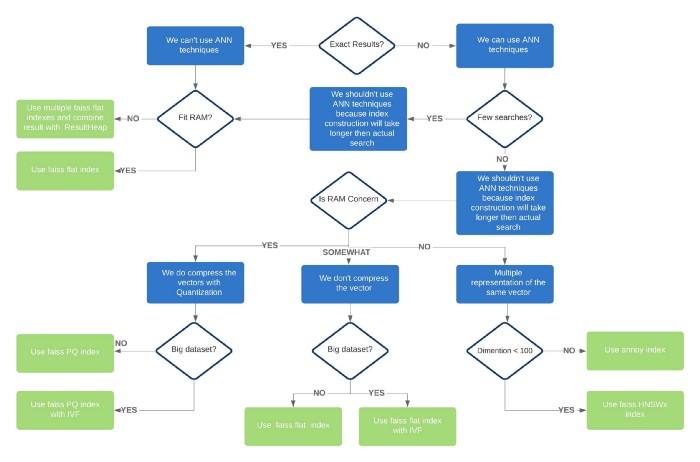
Here there is a useful schema that chould help which technique or implementation to use: