PLSA
Created: 2022-05-09 16:08
#note
Probabilistic Latent Semantic Analysis (PLSA) uses a probabilistic method instead of SVD to tackel LSA's problems.
The core idea is to find a probabilistic model with latent topics that can generate the data we observe in our document-term matrix. In particular, we want a model P(D,W) such that for any document d and word w, P(d,w) corresponds to that entry in the document-term matrix.
To the assumtions typical of topic modeling, PLSA adds the following ones:
- given a document d, topic z is present in that document with probability P(z|d);
- given a topic z, word w is drawn from z with probability P(w|z).
The joint probability of seeing a given document and a word together is: $P(D,W)=P(D)\sum_ZP(Z|D)P(W|Z)$. P(D) can be determined directly from the corpus, while P(Z|D) and P(W|Z) are modeled as multinomial distributions and can be trained using the expectation-maximization algorithm.
P(D,W) can be also parametrized as follows: $P(W,D)=\sum_ZP(Z)P(D|Z)P(W|Z)$. This last version can be compared to an LSA model as in the following image PLSA.PNG.
This underlies the fact that PLSA is just a LSA model, plus a probabilistic treatment of topics and words. This adds flexibility, but there are still problems with this model, in particular: since we don't have parameters to descrive P(D), we can't assign probabilities to new documents, and the number fo parameters gorws linearly with the number of documents, so it can overfit.
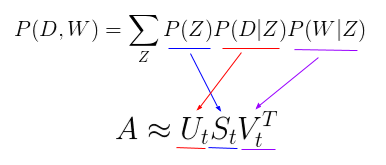{kind=link}
LDA generally performs better.