Concept
Created: 2022-07-01 08:50
#note
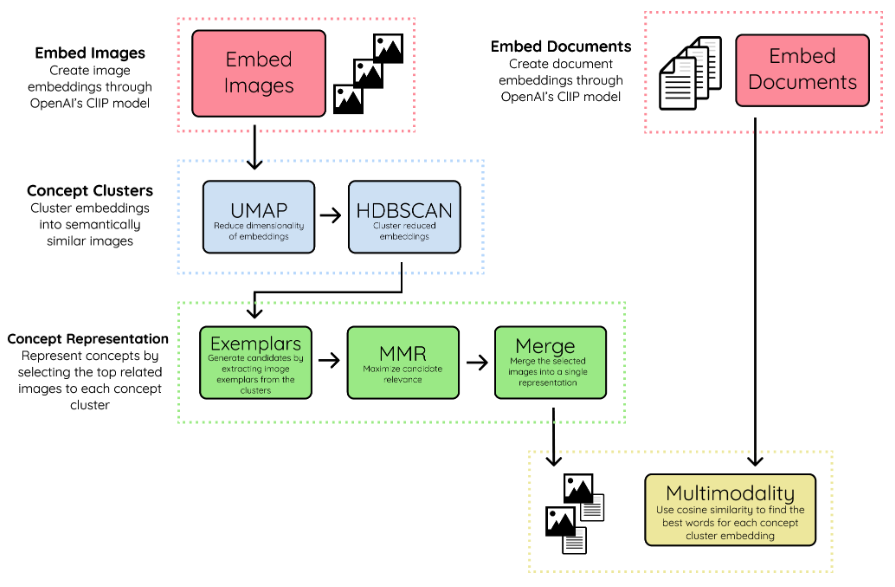
Steps:
- Both images an documents are both embedded into the same vector space using OpenAI's CLIP model;
- Using UMAP+HDBSCAN the image embeddings are clustered to create clusters of visually and semantically similar images. Clusters are called concepts;
- To pick representative images of clusters (exemplars), the most related images to each concept are taken. Maximal Marginal Relevance is used for this taask. The selected images are then combined into a single image to create a single visual representation;
- Textual embeddings are compared with the created concept cluster embeddings. Cosine similarity or c-TF-IDF can be used to select the embeddings that are most related to one another.