Combined Topic Modelling
Pre-training is a Hot Topic, Contextualized Document Embeddings improve Topic Coherence
Created: 2022-05-09 11:49
#paper
In this paper the authors combine contextualized representations with neural topic models. This improves topic coherence in a significant way. The model is called Combined Topic Model (CTM).
The most interesting thing about this method is that it has a cross-lingual zero-shot topic model (ZeroShotTM) that can first learn topics in English and then predict topics for documents in another language (in the same domain).
Moreover, most topic models cannot deal with unseen words because are based on BoW representations.
Main idea
CTM (and ZeroShotTM) is built around two components:
- Neural topic model ProdLDA;
- Sentence BERT.
Note: other topic models or pre-trained representations can be used, as long as the topic model extends an autoencoder and the pre-trained representations embed the documents.
The pre-trained representation of the document is passed to the neural architecture and then used to reconstruct the original BoW of the document. If a multilingual pre-trained representation is used during training, the same embedding space allows the model to learn topic representations that are shared by documents in different languages.
In deep
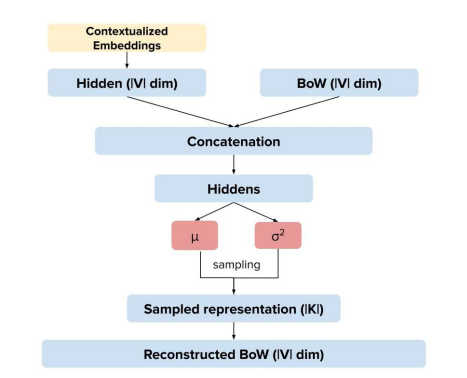{kind=link}
This model can be seen as an extention of ProdLDA, which is based on a Variational Autoencoder. ProdLDA takes as input the BoW representation of the documents and learns two parameters, $\mu$ and $\sigma^2$ of a Gaussian distribution. Then a continuous latent representation is sampled from these parameters and then passed through a softplus to obtain the document-topic distribution of the document. This topic-document representation is used to reconstruct the original document BoW representation. In this model, instead of the BoW representation, a pre-trained document representation is used.
As #cluster_metrics normalized pointwise Mutual Information, external word embeddings topic coherence and inverse rank-biased overlap are used.