Chameleon
Created: 2022-06-14 11:15
#paper
Main idea
Chameleon is an Hybrid Filtering Meta-Architecture for personalized news recommendations that deals with Deep Sequential RS/aware RS and Deep feature extraction from heterogeneous data.
Problems with RS on news:
- sparse user profiling -> majority of users are anonymous, so the user-item matrix can be really sparse and we do not have much information on past behaviours;
- fast growing number of items -> cold start problem for new items;
- items' value decay -> users are interested in fresh information;
- user preferences shift -> some users may change their domain of interests and current interest can be affected by user's context or global context.
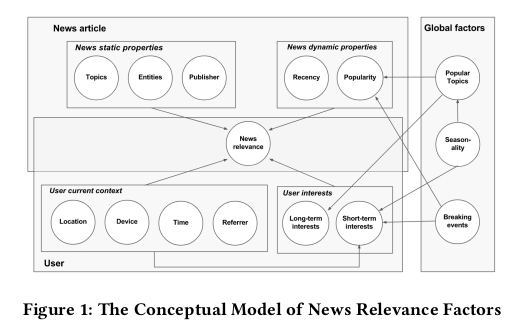
News articles have some static properties regarding its content (title, text, topics and mentioned entities). Publisher reputation may also add trust or discredit to an article.
News articles also have dynamic properties (i.e. properties that change over time) like popularity and recency. Global factors that might affect the article popularity are usually related to breaking events. Some enets are seasonal,, others are popular regardless of the period.
Short-term interests are influenced by location, device and time.
Long-term interests are usually stable, because they are related to personal preferences.
One of the main inspirations for this paper was the GRU4REC paper.
Another importart paper is: MV-DNN, which maps users and items to a latent space where we do not need to add new units into the output layer for each new item.
The CHAMELEON Meta-Architecture should be able:
• RQ1 - to provide personalized news recommendations in extreme cold-start scenarios, as most news are fresh and most users cannot be identified;
• RQ2 - to use Deep Learning to automatically learn news representations from textual content and news metadata, minimizing the need of manual feature engineering;
• RQ3 - to leverage the user session information, as the sequence of interacted news may indicate user’s short-term preferences for session-based recommendations;
• RQ4 - to leverage users’ past sessions information, when available, to model long-term interests for session-aware recommendations;
• RQ5 - to leverage users’ contextual information as a rich data source, in such information scarcity about the user;
• RQ6 - to model explicitly contextual news properties – popularity and recency – as those are important factors on news interest life cycle;
• RQ7 - to support an increasing number of new items and users by incremental model retraining (online learning), without the need to retrain on the whole historical dataset;
• RQ8 - to provide a modular structure for news recommendation, allowing its modules to be instantiated by different and increasingly advanced neural network architectures.
In deep
Chameleon deals and uses all this aspects + supports incremental online learning from mini-batches. Modularity was a main concern of the architecture.
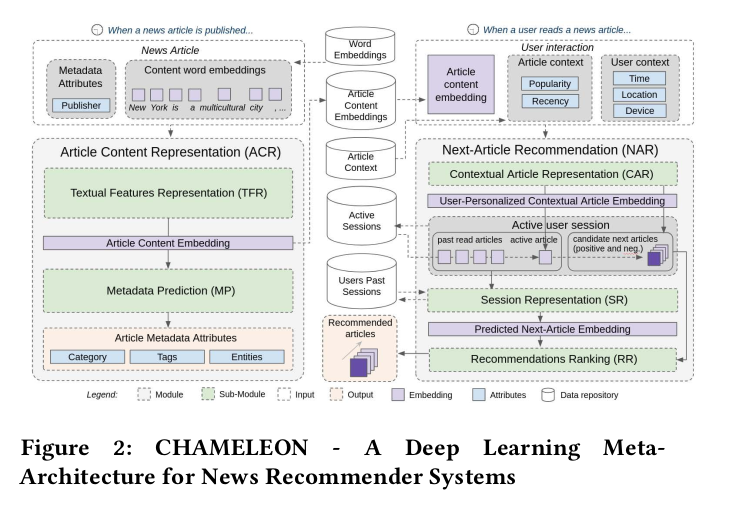
Chameleon can be seen as divided as two modules: the Article Content Representation (ACR) and the Next-Article Recommendation (NAR).
The ACR module learns the embeddings for news' contents.
The NAR module provides news articles recommendations for active user sessions.
Item IDs and user IDs are not used, just users' contextual information, interactions in the current sessions (+ past sessions information). To represent the content of items, (pre-trained) Article Content Embeddings (ACE) is used.
The inputs for the NAR module are:
- pre-trained ACE of the last interacted article;
- contextual properties of the article (popularity and recency);
- user context.
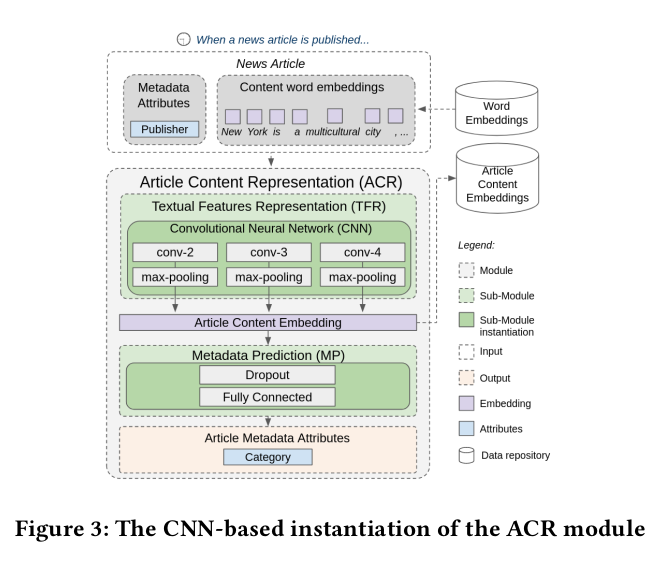
The ACR module uses CNNs for feature extraction from textual data. The inputs are: article metadata and word embeddings (computed with Word2Vec, GloVe).
NAR module uses RNNs to model the sequence of user interactions. More details here.
The chosen model from the RNNs family is UGRNN (a compromise between LSTM and GRU).
The first step of NAR produces the so called User-Personalized Contextual Article Embedding using the content of the news and context information.
The goal is then to maximize the similarity between the Predicted Next-Article Embedding and the User-Personalized Contextual Article Embedding corresponding to the next article actually read by the user in his or her session (positive sample), whilst minimizing its similarity with negative samples (articles not read by the user during the session).
The loss function was originally design to optimize accuracy, but there is also a version that balances accuracy and novelty.
The inputs for the NAR module are represented as i for the article ID, uc for the user context, ax for the article context and ac for the article textual content. Given these inputs, the User-Pesonalized Contextual Article Embedding is defined as $cae=\Psi(i,ac,ax,uc)$, where $\Psi()$ is a sequence of fully connected layers with non-linear activation functions.
The user session is represented with s, while the Predicted Next-Article Embedding is defined as $nae=\Gamma(s)$, with $\Gamma()$ is the output embedding predicted by the RNN.
The relevance of an item i for a given user session s is described by $R(s,i)=sim(nae,cae)$, where the $sim()$ function was the cosine similarity in the first implementation and an element-wise product of the embeddings in the last implementation (i.e. $sim(nae,cae)=\phi(nae \odot cae)$). $\phi()$ consists of a sequence of 4 feed-forward layers with a Leaky ReLU activation function.
The final task of the NAR module is to produce a ranked list of items, so we need to define a ranking-based loss function. D is the set of all items that can be recommended. The goal is to maximize the similarity between the predicted next article embedding (nae) for the session and th cae vector of the next-read article (positive sample, denoted as $i^+$), while minimizing the pairwise similarity between the nae and the cae vectors of the negative samples $i^- \in D^-$, i.e. those that were not read by the user in the session. Since D can be large, so we approximate it to a set D' which is the union of the unit set of the read articles and a set with random negative samples from $D^-$.
The posterior probability of an article being the next one given an active user session is computed with a softmax function over the relevance scores: $P(i|s,D')=\dfrac{e^{(\gamma R(i,s))}}{\sum_{\forall i' \in D'}e^{\gamma R(i',s)}}$, where $\gamma$ is a smoothing factor (aka temperature) for the softmax function, which can be trained on a held-out dataset or which can be empirically set. Given these definitions, the model parameters $\theta$ in the NAR module are estimated to maximize the accuracy of the recommendations. The corresponding loss function to be minimized is: $accuracy_loss(\theta)= \dfrac{1}{|C|} \sum_{(s,i^+,D')\in C}-\log(P(i^+|s,D'))$, where C is the set of user clicks available for training, whose elements are triples of the form $(s,i^+,D')$. Since $accuracy_loss(\theta)$ is differentiable w.r.t. to $\theta$, back-propagation with gradient-based optimization can be used.
In order to include novelty measures in the learning process, a novelty regularization term is included in the loss function. Through the hyper-parameter of this regularization term we can balance novelty and accuracy. Novelty is considered as the inverse popularity of an item. The positive items (actually clicked by the user) are not penalized based on their popularity, only the negative samples. The novelty of the negative items is weighted by their probabilities to be the next item in the sequence. The novelty loss component is defined as: $noc_loss(\theta)=\dfrac{1}{|C|}\sum_{(s,i^+,D^{'-})\in C}\dfrac{\sum_{i \in D^{'-}}P(i|s,D^{'-})\times novelty(i)}{\sum_{i \in D^{'-}}P(i|s,D^{'-})}$, where C is the set of recorded click events for training, $D^{'-}$ is a random sample of the negative samples, not including the positive sample as in the accuracy loss function. The novelty values of the items are weighted by their predicted relevance $P(i|s, D^{'-})$ in order to push both novel and relevant items towards the top of the recommendation list. The novelty metric is defined as the recent normalized popuarity of the items -> $novelty(i)=-\log_2(rec_norm_pop(i)+1)$, where the negative logarithm increases the value of the novelty metric for long-tail items. The normalized popularity is given by $rec_norm_pop(i)=\dfrac{recent_clicks(i)}{\sum_{j \in I}recent_clicks(j)}$ -> we are interested in the recent popularity, so we consider the clicks an article has received within a time frame, as returned by the function $recent_clicks()$.
So, the complete loss function proposed combines the two approaches in: $L(\theta)= accuracy_loss(\theta)-\beta \times nov_loss(\theta)$, where $\beta$ is an hyper-parameter for novelty.
Experimental setup, metrics and results are from this paper.
Evaluation protocol
The evaluation process is structured in the following way:
- The recommenders are continuously trained on user sessions ordered by time and grouped by hours. Every five hours, the recommenders are evaluated on sessions from the next hour. With this interval of five hours (not a divisor of 24 hours), we cover different hours of the day for evaluation. After the evaluation of the next hour was done, this hour is also considered for training, until the 2 entire dataset is covered.6 Note that CHAMELEON’s model is only updated after all events of the test hour are processed. This allows us to emulate a realistic production scenario where the model is trained and deployed once an hour to serve recommendations for the next hour;
- For each session in the test set, we incrementally reveal one click after the other to the recommender;
- For each click to be predicted, we sample a random set containing 50 recommendable articles (the ones that received at least one click by any user in the preceding hour) that were not viewed by the user in their session (negative samples) plus the true next article (positive sample). We then evaluate the algorithms for the task of ranking those 51 items. The sampling method for the 50 randomly chosen samples is popularity-biased, so that strong popularity negative samples are always present;
- Given these rankings, standard information retrieval (top-n) metrics can be computed.
Metrics
As metrics, accuracy, item coverage, novelty and diversity are considered, all measured at list length 10.
For accuracy, Hit Rate (HR@n) and Mean Reciprocal Rank (MRR@n) are used.
HR@n checks whether or not the true next item appears in the top-n ranked items.
MRR@n, instead, is also sensitive to the position of the next true item.
Item Coverage (COV@n) is important to assure that our recommender system does not focus just on a small subset of items. It is computed as the number of distinct articles that appeared in any top-n list divided by the number of recommendable articles (in this case articles viewed at least once in the last hour by any user).
Novelty is measured thanks to ESI-R@n metric, that is based on item popularity and returns higher values when long-tail items are among the top-n recommendations. It is also considered a version that considers both novelty and accuracy (ESI-RR@n), as the relevant (clicked) item will have a higher impact on the metric if it is among the top-n recommended items.
Diversity is measured using the Expected Intra-List Diversity (EILD-R@n) metric. Also in this case there is a variant for both rank- and relevance-sensitivity (EILD-RR@n).
Differences with my RS
- In KuriU, users are not anonymous -> we can use past sessions interactions and user profiles -> long term preferences;
- Our posts do not become outdated as quickly as can happen with news recommendations;
- Older posts can be proposed in recurrent periods (a post about skiing can still be useful during winter even if old)