Matrix Factorization
Created: 2022-04-25 11:25
#note
It consists in a representation of user-item as a vector of latent features which are projected into a shared feature space. User-item interactions are modeled using inner product of user-item latent vectors.
It can be enhanced by integrating it with neighbour based models, by combining it with topic models of item content and by extending it to factorization machines for general modeling of features.
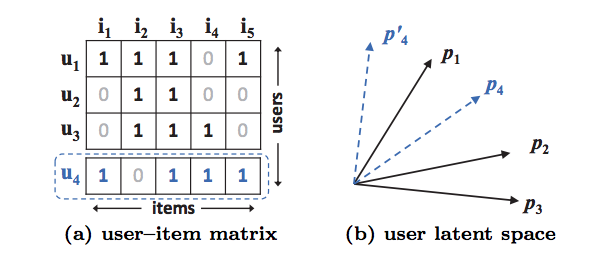
Performance can be improved by incorporating user-item bias terms into the interaction function -> to capture the complex structure of user interaction data we need something more than inner product.
Mathematical speaking, MF is represented as: $\hat{y}{ui}=f(u,i|p_u,q_i)=p_u^Tq_i=\sum{k=1}^{K}p_{uk}q_{ik}$, where $p_u$ is the latent vector for user u, $q_i$ is the latent vector for item i, $K$ is the dimension of the latent space.
A limitation of MF approach is show in the following image:
References
Code
Tags
#matrix_factorization