Unlock LLMs' Potential
Created: 2023-03-09 17:36
#note
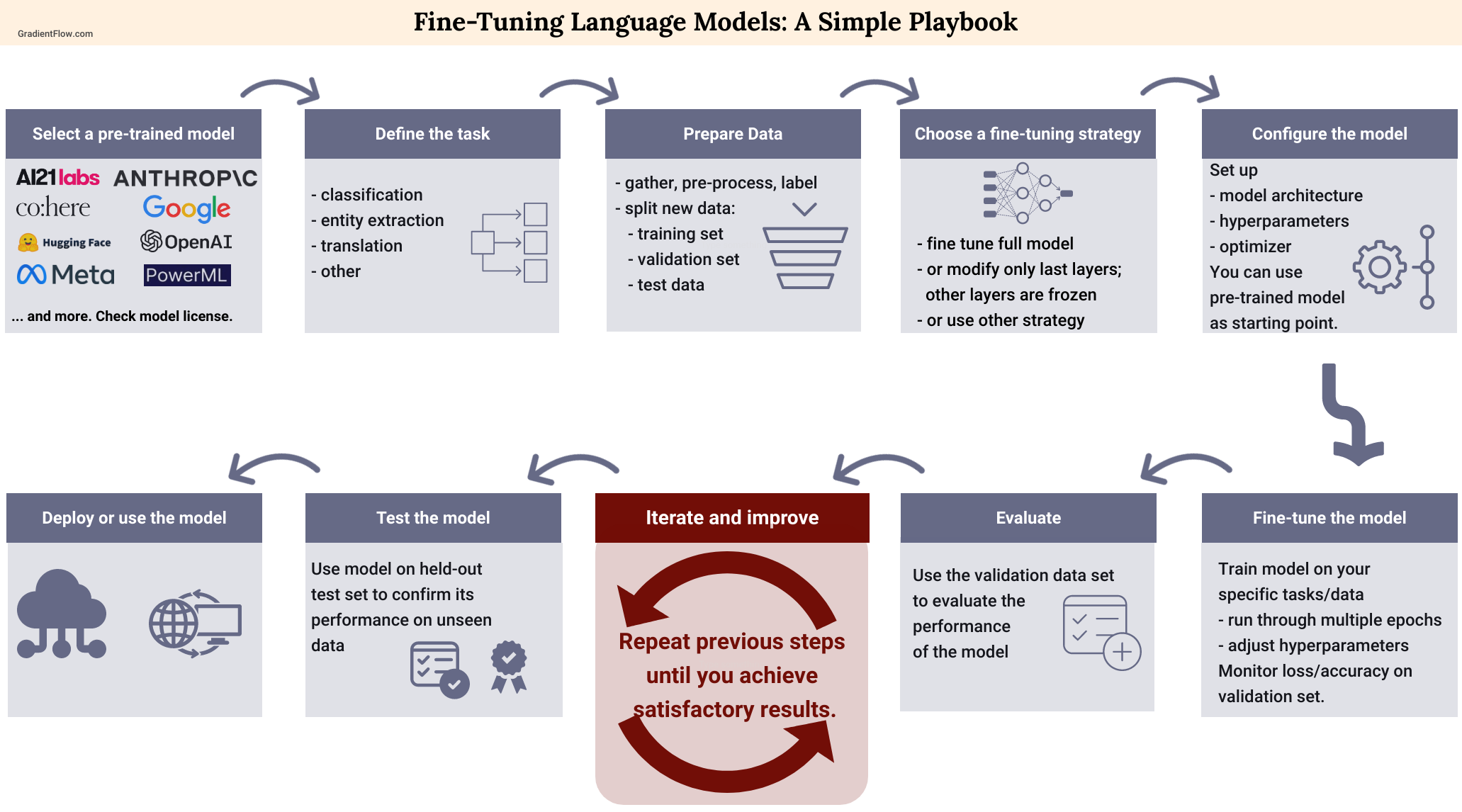
To truly take advantage of the potential of Large Language Models (LLMs) we have to adapt them for our tasks. For most teams, the best option is to use an established model and hone it to fit a particular task or dataset.
There are several ways to do such thing, but mainly we can find three classes of approaches:
- Tuning;
- Prompting;
- Reward-based techniques
Tuning (or Fine-Tuning) can be seen as a particular kind of transfer learning approach, much less onerous (we do not want to re-trained such enormous models, other people already trained them for us :) ). Some methods train some additional parameters that are added to the original models, without modifying the starting parameters (PEFT approach).
Prompting involves the careful selection and arrangement of words within a prompt or query in order to guide the model towards producing the desired response. Sometimes is referred as In-Context Learning.
In PEFT - Parameter-Efficient Fine-Tuning there is a comparison between subclasses for the first and second types.
The most famous approach from the third class, Reward-based techniques, is certainly Reinforcement Learning from Human Feedback (RLHF), the one used for ChatGPT, Bard, and so on.

Although RLHF has gained traction among teams building cutting-edge language models, its accessibility remains limited due to the lack of available tools. Furthermore, RLHF requires the development of a reward function that is vulnerable to misalignment and other issues, and remains a specialized technique that only a few teams have mastered.
Another interesting trend is the emergence of more manageable foundation models, such as LlaMA and Chinchilla, which open up possibilities for more mid-sized models in the future.