PEFT - Parameter-Efficient Fine-Tuning
Created: 2023-03-07 17:48
#note
Large Language Models (LLMs) based on the Transformer architecture are considered SOTA in several NLP (and not only) tasks. A typical way to use such models is to fine-tune large-scale pretrained generic models to downstream tasks. Fine-tuning could lead to huge performance improvements.
However, these models are really big, so fine-tuning and storing them on regular hardware can be a problem.
PEFT approaches could solve these problems by fine-tuning just a small amount of extra model parameters while keeping intact most of the parameters of the pretrained models.
This helps with the computational and storage costs, and also it can avoid the issue of catastrophic forgetting, where a pretrained model, once trained on a second task, "forgets" how to perform the first task.
PEFT techniques have also shown better results in low-data regimes and in out-of-scenarios contexts.
The small trained weights from PEFT approaches are added on top of the pretrained LLM. So the same LLM can be used for multiple tasks by adding small weights without having to replace the entire model. This also means that users get just tiny checkpoints after a PEFT (compared to large checkpoints of full fine-tuning, e.g. few MBs vs tens of GBs).
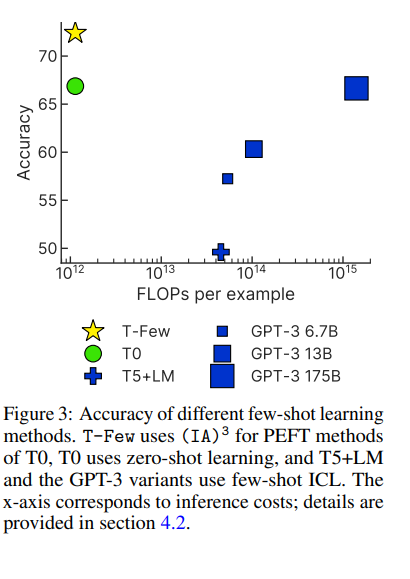
Few-shot Parameter-Efficient Fine-Tuning (PEFT) vs In-Context Learning (ICL)
ICL approaches are fine-tuning techniques that feeds a small number of training examples as part of the input (==prompted examples==) to the model to make it able to perform a previously-unseen task. This process does not need any gradient-based training, it relies on the capabilities that a model learned during pre-training.
Since it involves a processing of all the training examples every time a prediction is made, it has substantial computational, memory, and storage ==costs==. Also, classical fine-tuning techniques generally obtain better results, and studies report that ICL can perform well even when provided with ==incorrect labels==, raising questions as to how much learning is taking place at all.
ICL's inputs are concatenated and prompted input-target examples (called “shots”) with an unlabeled query example, e.g. “Please unscramble the letters into a word, and write that word: asinoc = casino, yfrogg = froggy, plesim = simple, iggestb = biggest, astedro =”.
An ==advantage== of ICL is that it enables mixed-task batches, where different examples in a batch of data correspond to different tasks by using different contexts in the input.
Processing the k training examples for k-shot ICL increases the computational cost by approximately k + 1 times compared to processing the unlabeled example alone. Memory costs similarly scale approximately linearly with k, though during inference the memory costs are typically dominated by storing the model’s parameters. Separately, there is a small amount of on-disk storage required for storing the in-context examples for a given task.
Another ==disadvantage== is that the ordering of examples in the context heavily influences the model's predictions.
Various approaches have been proposed to mitigate these issues (e.g. to decrease computational costs, cache the key and value vectors for in-context examples).
PEFT approaches demonstrate better accuracy as well as (==dramatically==) lower computational costs (e.g. 0.01% of the parameters are needed).
Furthermore, certain PEFT methods allow mixed-task batches where different examples in a batch are processed differently (here), but one thing to consider is that, generally, PEFT methods that re-parameterize the model are costly for mixed-task batches.
There are a plethora of PEFT approaches (adapters, prompt tuning, prefix tuning...), from now on we focus on the method proposed in Few-shot PEFT vs In-Context Learning $(IA)^3$ and the recipe $T-Few$, both built on top of the model T0 (a variant of T5).
NOTES:
- the rest of the note is taken from Few-shot PEFT vs In-Context Learning;
- by recipe, the authors mean a specific model and hyperparameter setting that provides strong performance on any new task without manual tuning or per-task adjustments;
- in order to easily enable mixed-task batches, a PEFT method should ideally not modify the model itself (otherwise, each example in a batch would effectively need to be processed by a different model or computational graph).
For evaluation, they use “rank classification”, where the model’s log-probabilities for all possible label strings are ranked and the model’s prediction is considered correct if the highest-ranked choice is the correct answer (the median accuracy across all prompt templates is reported). It depends on both the probability that the model assigns to the correct choice as well as the probabilities assigned by the model to the incorrect choices.
LLMs are usually trained using cross-entropy ($L_{LM}$), but the authors added two additional ==losses== to improve the performance of few-shot fine-tuning:
- unlikelihood loss ($L_{UL}$), with which the model will be trained to assign lower probabilities to incorrect choices, thereby improving the chance that the correct choice is ranked highest;
- length-normalized loss ($L_{LN}$), where we maximize the length-normalized log probability of the correct answer choice by minimizing the softmax cross-entropy loss (used because the possible target sequences for a given training example can have significantly different lengths, especially in multiple-choice tasks).
Using all three losses improve the performances.
The authors tested PEFT methods on various pre-trained models, the best results were given by T0.
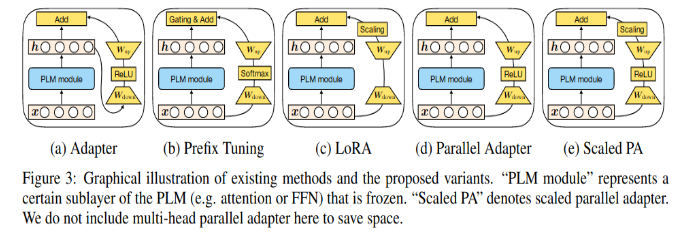
They tried several PEFT methods (like LoRA - Low-Rank Adaptation of LLMs) that allow mixed-task batches (e.g., prompt tuning and prefix tuning), but the results were not really good, while more performant methods did not allow for mixed-task batch -> they developed a new method: they introduced three learned vectors $l_k \in R^{d_k}, l_v \in R^{d_v}, l_{ff} \in R^{d_{ff}}$ which are introduced into the attention mechanism as follows: $softmax(\frac{Q(l_k \odot K^T)}{\sqrt{d_k}})(l_v \odot V)$ and in the position-wise feed-forward network as $(l_{ff} \odot \gamma(W_1x))W_2$, where $\gamma$ is the feed-forward network nonlinearity.
They introduce a separate set of $l_k, l_v, l_{ff}$ vectors in each Transformer layer block. This adds a total of $L(d_k + d_v + d_{ff})$ new parameters for a L-layer-block Transformer encoder and $L(2d_k + 2d_v + d_{ff})$ (with factors of 2 accounting for the presence of both self-attention and encoder-decoder attention) for a L-layer-block decoder. $l_k, l_v, l_{ff}$ are all initialized with ones so that the overall function computed by the model does not change when they are added.
They call this method $(IA)^3$ , which stands for “Infused Adapter by Inhibiting and Amplifying Inner Activations”.
$(IA)^3$ makes mixed-task batches possible because each sequence of activations in the batch can be separately and cheaply multiplied by its associated learned task vector.
They compared their method with other PEFT methods and few-shot learners.
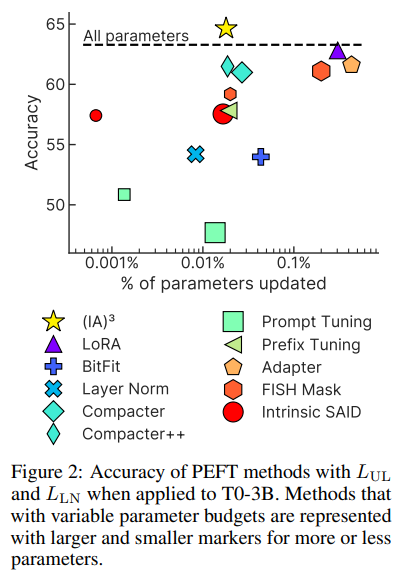
Some studies showed that pre-training the prompt embeddings can improve performance, so $(IA)^3$ was pre-trained on the same multitask mixture used to train T0. Results improved by ~1 point.
T-Few recipe is defined as follows:
- use T0 as backbone;
- add $(AI^3)$ for downstream task adaptation and pre-trained it on the same multitask mixture used for T0;
- As an objective use $L_{LM} + L_{UL} + L_{LN}$;
- train (1000 steps, batch size of 8 sequences using Adafactor optimizer with learning rate of $3e^{-3}$, linear decay schedule with 60-step warmup).
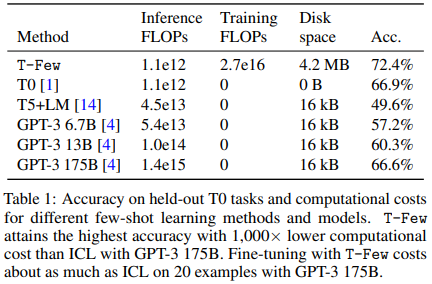
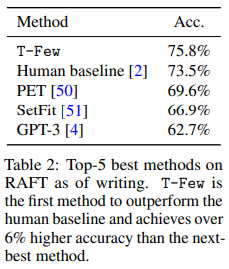
Note (from the tables above) that T-Few is the only method that involves updating parameters, so it is the only method that incurs a training cost. While not insignificant, this is only about 20 times larger than the FLOPs required to process a single example with few-shot ICL using GPT-3 175B.
For the broader landscape of LLM post-training and alignment techniques beyond parameter-efficient methods, see LLM Training and Alignment Evolution, which covers RLHF - Reinforcement Learning from Human Feedback, DPO - Direct Preference Optimization, and newer approaches like RLVF - Reinforcement Learning from Verifiable Feedback.