Adaptive Machine Translation With LLMs
Created: 2023-03-15 16:31
#paper
Main idea
The authors conducted several months of experiments to find out whether GPT-3 is capable of enhancing Adaptive Machine Translation, defined as simultaneously improving the quality of new translations based on user feedback.
User feedback can take several forms, including corrections to previous translations, terminology and style guides, and ratings of translation quality.
They also explored a less common method of adaptive MT: learning from similar translations (i.e., fuzzy matches) found in approved Translation memories. In particular, researchers were interested in real-time adaptation.
Tasks:
- Adapting new translations to match the terminology and style of previously approved TM fuzzy matches, at inference time;
- Matching or outperforming the quality of translations generated by encoder-decoder MT models across a number of languages;
- Fixing translations from stronger encoder-decoder MT systems using fuzzy matches, which is especially useful for low-resource languages;
- Terminology-constrained MT, by first defining terminology in the relevant sentences or dataset, and then forcing new translations to use these terms.
Results
Generally speaking, results obtained from these experiments are very promising. While some high-resource languages such as English-to-French, English-to-Spanish and even English-to-Chinese show excellent results, other languages have lower support either because they are low-resource languages such as English-to-Kinyarwanda or because of issues in the GPT-3 tokenizer such as English-to-Arabic.
Nevertheless, when they used GPT-3.5 for MT post-editing of the English-to-Arabic translation obtained from OPUS, the quality significantly surpassed that obtained from both OPUS and Google Translation API.
This means that different pipelines can be adopted in production for different language pairs, based on the level of support of these languages by an LLM.
Ideas for future works
- experiment with more open-source LLMs;
- use dynamic few-shot example selection, i.e. do not fix the number of fuzzy matches but retrieve and use all the high-quality fuzzy matches;
- similar thing with terms from glossaries;
- extract phrases instead of terms in terminology extraction;
- fine tune LLMs and then use prompting as done in this work.
In deep
To retrieve fuzzy matches, the authors used paraphrase mining from the Sentence Transformer library, and for each sentence they retrieve up to top_k other sentences. Using fuzzy n-shot when translating improves the performance (with diminishing returns of adding more similar sentences).
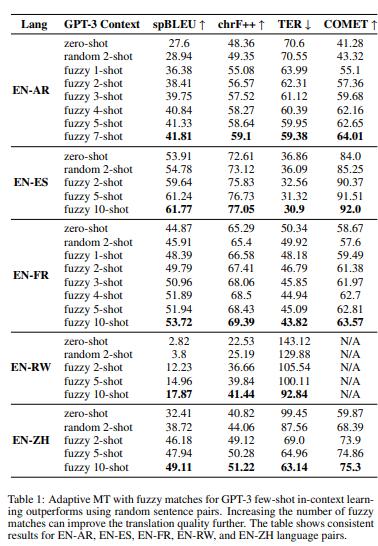
GPT-3 vs Encoder-Decoder MT models
GPT-3 zero-shot, GPT-3 fuzzy 5-shot, and GPT-3 fuzzy 7-shot are compared to several Encoder-Decoder MT models like ModernMT. Except for English-to-Arabic, GPT-3 with fuzzy 10-shot outperforms ModernMT and all he other models. The zero-shot version of GPT is generally worse than ModernMT.
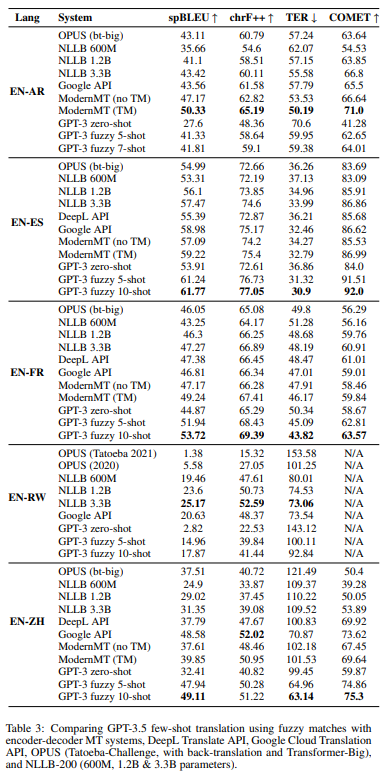
Enhance GPT using MT Encoder-Decoder models
There are two ways to do such thing:
- append fuzzy matches with a translation from an MT model to the prompt
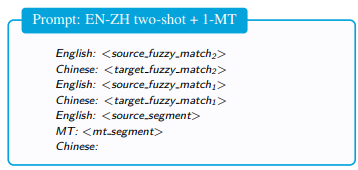 ;
; - use MT translations in the prompt for all the fuzzy matches and the new source segment to be translated

With the first method, we can improve results over the MT method, if GPT was not already significantly better (in that case the improvements are small).
With the second method, it is not clear if the results improve or not. It probably depends on the quality of the original MT.
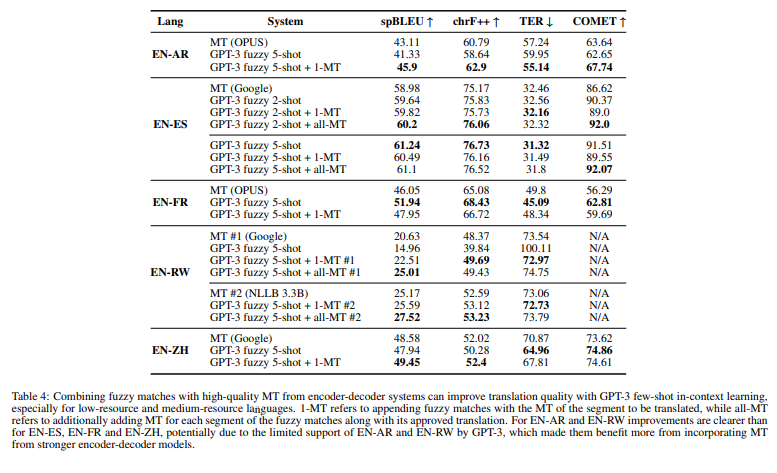
Bilingual Terminology Extraction
Terminology extraction is the task of automatically defining domain-specific terms in a dataset. It is possible to improve MT performance through finding sentences that include these terms and fine-tuning the system with them.
The authors tested GPT-3 to extract 5 bilingual terms from each sentence pair in the context dataset. The majority of the terms in the provided sample were accurately extracted by the model.

Terminology-Constrained MT
In case we do not have many fuzzy matches, we could incorporate domain-specific terminology to improve the translations. A pre-approved glossary can be used, if available, or, instead, a terminology extraction process, like the one explained in the previous paragraph, can be used.
Three scenarios are investigated:
- 2 fuzzy matches and their terms. Since they did not have terms for the segment to be translated, they used terms from the 2 fuzzy matches if they are found in a set of n-grams of the source segment to be translated. This approach outperform the usage of just fuzzy matches;
- automatically compile a glossary including all the terms from the dataset, with 2+ frequency and up to 5-grams. The list is sorted by n-gram length, so terms with longer n-grams are prioritized. This approach outperform the first proposed method (maybe because of the diversity of terms);
- Zero-shot translation, i.e. without any fuzzy matches. Similar to the second scenario, but with just terms from the glossary. Including terms from the glossary improves the results.
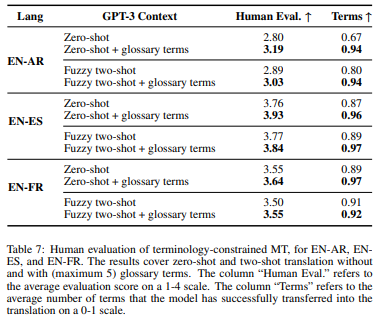
For this part, the results were evaluated by professional linguists (sentence-level translation quality is evaluated on a 1-4 scale and the usage of each provided term in the translation on a 0-1 scale).
In several cases, forcing glossary terms to be used could help improve the overall translation quality; however, sometimes it was detrimental to grammatical accuracy. In particular, , it might be better to exclude shorter terms if they overlap with longer ones.
Among interesting observations that human evaluation reveals is that in few-shot translation with fuzzy matches (even without terms), the number of successfully used terms is more than those in zero-shot translation.
Moreover, incorporating glossary terms in a zero-shot prompt can result in quality gains comparable to those of few-shot translation with fuzzy matches.
BLOOM and BLOOMZ
With 2 fuzzy matches, GPT-3 is generally better than both models, except for English-to-Arabic. Surprisingly, BLOOMZ is worse than BLOOM.
References
Code
Tags
#llm #dl #finetuning #machinetranslation