LoRA - Low-Rank Adaptation Of LLMs
Created: 2023-03-21 09:48
#paper
Main idea
LoRA is a PEFT method that consists in freezing the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture.
Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on-par or better than finetuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency.
Normal adapter: 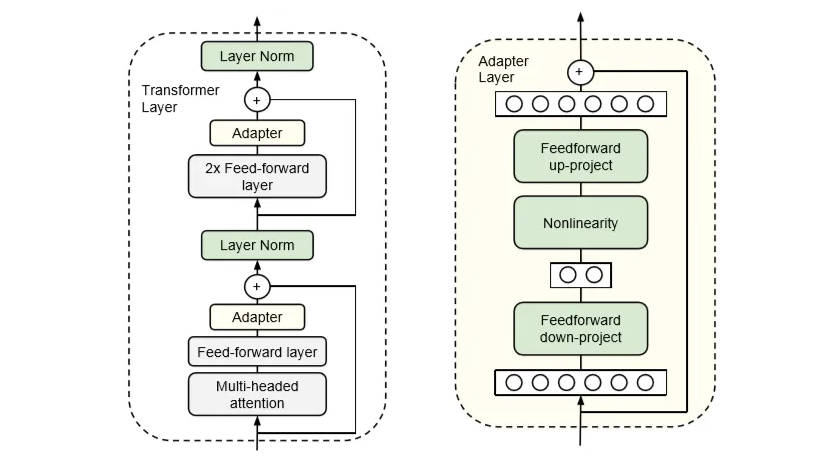
LoRA: 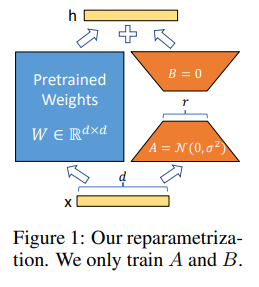
Results
Advantages:
- a pre-trained Large Language Models (LLMs) can be shared between many small LoRA modules for different tasks, we just need to replace matrices A and B (figure above);
- trainings are much more efficient -> we have to optimize just the injected smaller low-rank matrices;
- the trainable matrices and the frozen weights can be merged when deployed, introducing no inference latency;
- LoRA can be combined with other PEFT methods (e.g. prefix-tuning).
Ideas for future works
- LoRA can be combined with other efficient adaptation methods, potentially providing orthogonal improvement.
- The mechanism behind fine-tuning or LoRA is far from clear – how are features learned during pre-training transformed to do well on downstream tasks? We believe that LoRA makes it more tractable to answer this than full fine tuning.
- We mostly depend on heuristics to select the weight matrices to apply LoRA to. Are there more principled ways to do it?
- Finally, the rank-deficiency of ∆W suggests that W could be rank-deficient as well, which can also be a source of inspiration for future works.
In deep
Problems with Adapters:
- inference latency -> even if adapters add few parameters to the model, their layers have to be processed sequentially and this could be a problem in the online inference setting. Other problems arise when the model needs to be sharded;
- directly optimizing the prompt is hard (sequence length that can be used for adaptation is limited)
A neural network contains many dense layers which perform matrix multiplication. The weight matrices in these layers typically have full-rank. When adapting to a specific task, Aghajanyan et al. (2020) shows that the pre-trained language models have a low “instrisic dimension” and can still learn efficiently despite a random projection to a smaller subspace.
Inspired by this, the authors wanted the updates to have a low "intrinsic rank" during adaptation.
Given a pre-trained matrix $W_0 \in R^{d \times k}$, the update is constrained by representing it with a low-rank decomposition: $W_0 + \Delta W = W_0 + BA$, where $B \in R^{d \times r}, A \in R^{r \times k}$, and the rank $r << min(d,k)$.
During training, $W_0$ is frozen and does not receive gradient updates, while A and B contain trainable parameters. Note both $W_0$ and $\Delta W = BA$ are multiplied with the same input, and their respective output vectors are summed coordinate-wise. For $h = W_0x$, our modified forward pass yields: $h = W_0x + \Delta W x = W_0x + BAx$.
LoRA does not need the accumulated gradient update to weight matrices to have full-rank during adaptation. This means that when LoRA is applied to all weight matrices, the expressiveness of full fine-tuning is roughly recovered by setting the LoRA rank r to the rank of the pre-trained weight matrices.
The authors limit the study to only adapting the attention weights for downstream tasks and freeze the MLP modules (so they are not trained in downstream tasks) both for simplicity and parameter-efficiency.
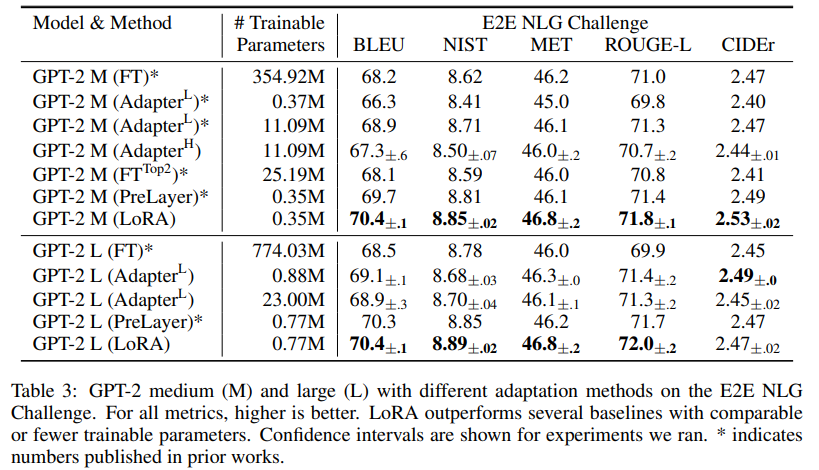
For GPT-3 training is 25% faster and the checkpoint weights 10.000x less.
References
Code
Tags
#llm #peft #finetuning