FrugalGPT
Created: 2023-05-11 14:24
#paper
Main idea
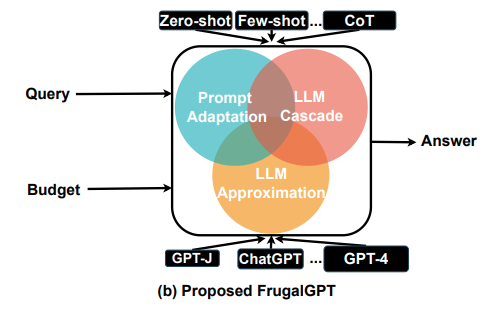
FrugalGPT is a framework that uses Large Language Models (LLMs) APIs to process natural language queries within a budget constraints.
Results
The tests were done on three datasets (HEADLINES, OVERRULING, COQA), 12 LLM APIs from 5 providers (OpenAI, AI21, CoHere, textsynth, ForeFront AI).
The results are generally better if compared to the outputs generated by only GPT4.
The metric used is MPI (maximum performance improvement). The MPI of LLM A with respect to LLM B is the probability that LLM A generates the correct answer while LLM B provides incorrect ones. This metric essentially measures the maximum performance gains achievable by invoking LLM A in addition to LLM B.
In the HEADLINES dataset, for example, GPT-C, GPT-J, and J1-L can all enhance GPT4's performance by up to 6%.
The authors say thar FrugalGPT can reduce costs by up to 98% while preserving the performance of cutting-edge LLMs (or can have 4% better results with same costs).
Ideas for future works
One limit of this idea is that to train LLM cascade in FrugalGPT we need some labeled examples.
This approach wants to optimize costs and performance but does not consider other critical factors in real-world applications, like latency, fairness, privacy, and environmental impact.
In deep
There are three main strategies for cost reduction:
Prompt adaptation: the cost of an LLM query increases linearly with the size of the prompt -> we want to decrease prompt's size. One way to do this is with prompt selection(a), where we retain a small subset of examples from a bigger pool of examples. The challenge lies in determining which examlpes to keep. Another approach is query concatenation (b), which consists in sending the prompt just ones for different queries (e.g. to handle two queries using one prompt, the examples presented in the prompt can include both queries followed by their corresponding answers);
LLM approximation: if an LLM API is too expensive to use, use another one or a cheaper infrastructure. For example, by using a cache (c) for queries, we can verify if a similar query has been previously answered. If so, the response is retrieved from the cache without invoking the API. Another approach consists in collecting responses from LLM API and use them to fine-tune smaller and cheaper models (d);
LLM cascade: a query is sent to a list of LLM APIs sequentially (e). If one LLM API's response is reliable, then its response is returned and no further LLMs in the list are needed. The remaining LLM APIs are queried only if the previous APIs’ generations are deemed insufficiently reliable. Query cost is significantly reduced if the first few APIs are relatively inexpensive and produce reliable generations. The scoring function can be obtained by training a simple regression model that learns whether a generation is correct from the query and a generated answer.
Compositions of these approaches can further improve cost reduction and performance.
References
Code
Tags
#dl #llm