Does Fine-Tuning LLMs On New Knowledge Encourage Hallucinations?
Created: 2024-06-08 11:26
#paper
Main idea
The goal of the paper is to check whether Fine Tuning Large Language Models (LLMs) could increase the tendency of the models to hallucinate.
Results
The results show that factual knowledge is mostly learned during the pre-training and with fine tuning we can use more efficiently this knowledge. As new examples are learned, the risk of hallucinations increases linearly (especially when the training starts to overfit).
In deep
The used dataset is defined as $D$, the model (PaLM 2) $M$, and $M_D$ is is the model $M$ trained on the dataset $D$. The goal is to study the performance of $M_D$ on variants of $D$ that contain several proportions of examples known to $M$. $D$ is defined as $D={(q_i,a_i)}^N_{i=1}$ where $q$ is a question and $a$ is the ground-truth answer. The QA are generated from EntityQuestions. The model used is PaLM 2-M base model and as evaluation metric exact match (EM) was the one chosen.
Quantify knowledge
To test the idea of the paper (i.e. fine-tuning on Unknown samples increases chances of hallucinations), every pair $(q,a)$ is annotated and divided into four knowledge categories -> this approach is called $SliCK$ (Sampling-based Categorization of Knowledge).
Note: the model is not instruct-tuned, so it was prompted using in-context learning with few-shot examples (examples should have high semantic similarity to $q$).
$P_{correct}(q;a;M;T)$ is an estimate of how likely is $M$ to accurately generate the correct answer $a$ to $q$, when prompted with random few-shot examples and using decoding temperature $T$.
The Unknown category is the set of samples $(q,a)$ for which $P_{correct}(q;a;M;T \geq 0)=0$.
The Known category is the set of samples$(q,a)$ for which $P_{correct}(q;a;M;T \geq 0)>0$.
The Known category is divided in Highly, Maybe, Weakly Known depending on the number of correct guesses.
Tests
To tests the effect of new knowledge in fine-tuning, the authors generated several versions on $D$ by varying the proportion of the Unknown examples in it.
Early-stop is based on the development set (generally happens after 5-10 epochs) and Convergence (i.e. 100% accuracy on training set) is set to 50 epochs.

The figure above (3a) presents the performance as a function of the % of Unknown examples in $D$, for different fine-tuning durations.
A higher proportion of Unknown examples in the dataset negatively impacts performance, irrespective of the fine-tuning duration. This suggests that Unknown examples are less valuable for training than Known examples.
The fine-tuning duration significantly influences performance, with early stopping often leading to the best results. Extended training typically worsens performance, likely due to overfitting. This effect becomes more pronounced with a higher proportion of Unknown examples, indicating a greater susceptibility to overfitting in such cases.
Figure 3b shows how harmful are Unknown examples. Using early stops, there is not evident difference between using new and unknown samples vs just known ones. With convergence we can easily notice instead the decreases in performance. Furthermore, the gap increases when the proportion of Unknown samples increases.
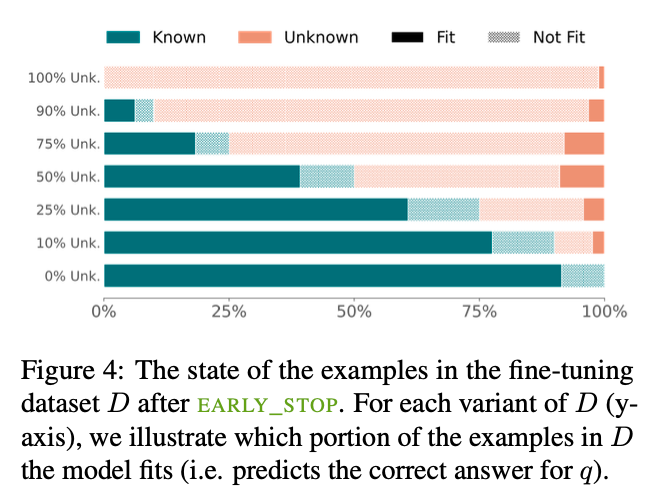
Another interesting aspect (figure above) is that $M$ fits Unknown fine-tuning examples substantially slower than Known. In early stop (vertical dotted line), M reaches peak performance on the development set, while fitting the majority of the Known examples but only a small fraction of the Unknown. That explains why the Unknown samples had a neutral effect on performance, $M$ did not fit them at all.
Since Unknown examples are harmful, one might expect that it would be best to fine-tune on the most exemplary HighlyKnown examples. Surprisingly, the best results are obtained with MaybeKnown examples and not HighlyKnown ones. WeaklyKnown samples are decreasing the performance.
Limitations\
- only 1 model tested
- one task
References
Tags
#llm #hallucination #finetuning