An Empirical Comparison Of Domain Adaptation Methods For NMT
Created: 2023-05-30 10:47
#paper
Main idea
In this paper a method called mixed fine-tuning is proposed to deal with the adaptation of NMT to in-domain corpora. This method should solve the overfitting problem that arises when fine-tuning with small in-domain data.
The idea consists in/:
- train an NMT model on an out-of-domain parallel corpus;
- fine-tune the model on a mix of the in-domain (oversampled) and the out-of-domain corpora.
All corpora are augmented with artificial tags to indicate the specific domain (multi domain NMT).
An additional fine-tuning on just the in-domain data can be done.
Note that in the “fine tuning” method, the vocabulary obtained from the out-of-domain data is used for the in-domain data; while for the “multi domain” and “mixed fine tuning” methods, the authors use a vocabulary obtained from the mixed in-domain and out-of-domain data for all the training stages.
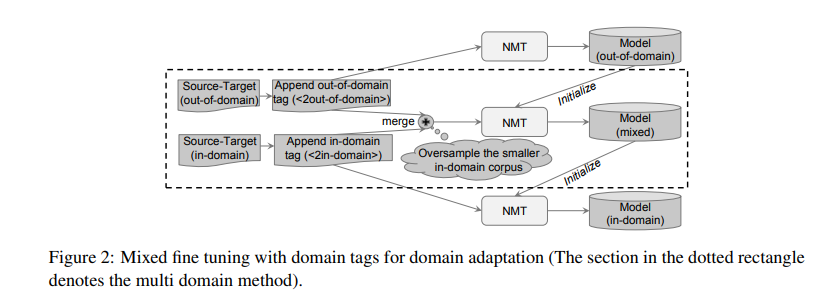
The patent domain MT was conducted on the Chinese-English subtask (NTCIRCE) of the patent MT task at the NTCIR-10 workshop.
The spoken domain MT was conducted on the Chinese-English subtask (IWSLT-CE) of the TED talk MT task at the IWSLT 2015 workshop.
Chinese-to-Japanese translation was the focus of the low quality in-domain corpus setting. They utilized the resource rich scientific out-of-domain data to augment the resource poor Wikipedia (essentially open) in-domain data. The scientific domain MT was conducted on the Chinese-Japanese paper excerpt corpus (ASPEC-CJ).
The NMT used is KyotoNMT.
Results
We can see that without domain adaptation, the SMT systems perform significantly better than the NMT system on the resource poor domains, i.e., IWSLT-CE and WIKI-CJ; while on the resource rich domains, i.e., NTCIR-CE and ASPECCJ, NMT outperforms SMT.
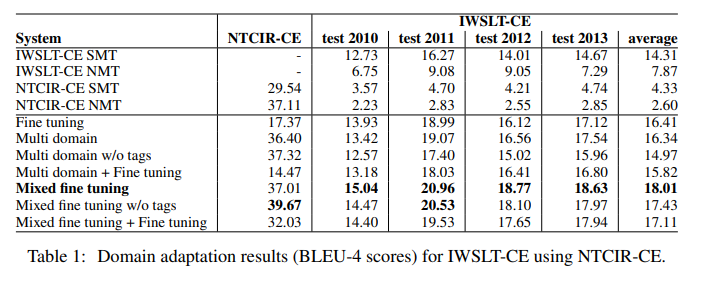
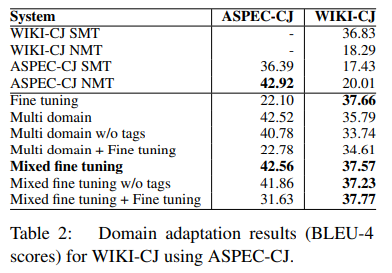
The domain tags are helpful for both “Multi domain” and “Mixed fine tuning.” Essentially, further fine tuning on in-domain data does not help for both “Multi domain” and “Mixed fine tuning.” They believe that there are two reasons for this. Firstly, the “Multi domain” and “Mixed fine tuning” methods already utilize the in-domain data used for fine tuning. Secondly, fine tuning on the small in-domain data overfits very quickly. Actually, they observed that adding fine-tuning on top of both “Multi domain” and “Mixed fine tuning” overfits at the beginning of training.
Ideas for future works
- incorporate an RNN model into our architecture to leverage abundant in-domain monolingual corpora;
- exploring the effects of synthetic data by back translating large in-domain monolingual corpora.
References
Tags
#nmt #finetuning