MemGPT - Towards LLMs As Operating Systems
Created: 2024-05-10 17:42
#paper
Summary
- MemGPT is a system designed to overcome the limitations of fixed context windows in Large Language Models (LLMs), drawing inspiration from virtual memory paging in operating systems.
- It utilizes function calls to manage context virtually, enabling LLM agents to interact with external data, modify their own context, and control their response timing.
- This allows the LLM agent to efficiently swap information in and out of its context window, similar to hierarchical memory in operating systems.
- MemGPT outperformed traditional LLM-based approaches in document analysis (where text length often exceeds LLM capacity) and conversational agents (where limited context hinders performance).
Main Idea
In MemGPT the multi-level memory architecture, typical of OSes, is divided into two primary types: main context, which can be compared to main memory/physical memory/RAM, and external context, analogous to main/disk storage.
The main context consists of the LLM prompt tokens, while the external context includes all the information that is outside of the LLM's fixed context window. MemGPT provides function calls that the LLM processor to manage its own memory without any user intervention.
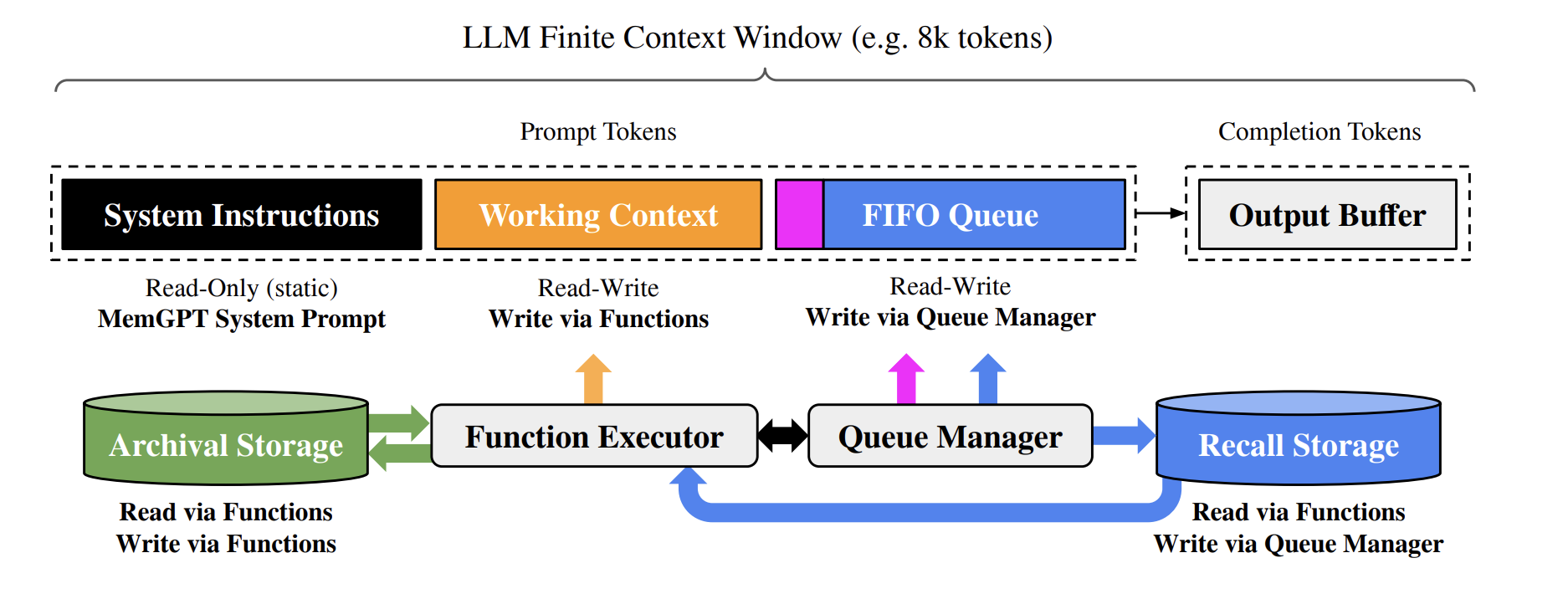
Main context
The main context (aka prompt tokens) is segmented into three contiguous sections:
- System Instructions: this read-only section contains static information about MemGPT's control flow, the designated purposes of various memory levels, and guidelines on utilizing MemGPT functions.
- Working Context: this section is a fixed-size block of unstructured text, accessible for both reading and writing, but modifications can only be made through MemGPT function calls. In conversational contexts, this space is meant to hold key details, preferences, and other relevant information about the user and the agent's adopted persona, facilitating smooth communication.
- FIFO Queue: this section functions as a message history, encompassing exchanges between the agent and user, along with system messages (such as memory warnings) and the inputs and outputs of function calls. The initial entry in this queue is a system message containing a recursive summary of messages that have been removed from the queue due to space constraints.
Queue Manager
The queue manager manages messages in the recall storage and the FIFO queue.
When a new message is received, the queue manager:
- appends it to the FIFO queue
- if a function call retrieves message in the recall storage, these are appended to the back of the queue to be reinserted into the LLM's context window
- concatenates the prompt tokens
- triggers the LLM inference to get an output
- writes both the incoming message and the output to the recall storage
The queue manager handles context overflow using a 'queue eviction policy'. When the prompt tokens go over the 'warning token count' (e.g., 70% of the context window), it adds a system message to the queue, warning the LLM that some items might be removed soon. This 'memory pressure' warning gives the LLM a chance to save important information from the FIFO queue to either the working context or the archival storage (a database for storing any amount of text).
When the prompt tokens reach the 'flush token count' (e.g., 100% of the context window), the queue manager removes items to free up space: it takes out a certain number of messages (e.g., 50% of the context window) and makes a new summary from the old summary and the removed messages. After this, the removed messages are not immediately visible to the LLM, but they are still saved in 'recall storage' and can be accessed later if needed.
Function executor
Function calls, generated by the LLM processor, orchestrate the movement of data between main context and external context. MemGPT can autonomously update and search through its own memory based on the current context.
Self-directed editing and retrieval are implemented by providing explicit instructions within the system instructions that guide the LLM on how to interact with the MemGPT memory systems. These instructions comprise two main components:
- a detailed description of the memory hierarchy and their respective utilities,
- a function schema (complete with their natural language descriptions) that the system can call to access or modify its memory.
In each 'inference cycle', the LLM processor takes the main context (concatenated into a single string) as input and creates an output string. MemGPT then checks this output to make sure it's correct. If the output is a valid function call, the function is run.
The results of the function, including any errors (like trying to add to the main context when it's full), are sent back to the processor by MemGPT. This feedback helps the system learn and change how it acts. Knowing the context limits is important for the self-editing to work well, so MemGPT warns the processor about token limits to help it manage memory better. Also, when getting information from memory, MemGPT uses 'pagination' to avoid bringing back too much at once and overflowing the context window.
Control flow and function chaining
LLM inference is triggered by events (user messages, system messages, user interactions, and timed events). MemGPT processes events with a parser to convert them into plain text messages that can be appended to main context and eventually be fed as input into the LLM processor.
Function chaining allows MemGPT to execute multiple function calls sequentially before returning control to the user. Functions can be called with a special flag that cause the control to be given to the processor, after the end of execution of the function. If the flag is not present, the LLM processor will not be run until the next trigger.
Experiments
The approach was tested on two long-context domains: conversational agents and document analysis.
For the first domain, the Multi-Session Chat dataset was expanded by introducing two new dialogue tasks that evaluate an agent’s ability to retain knowledge across long conversations.
For document analysis, the benchmarks are performed for question answering and key-value retrieval over lengthy documents. A new nested key-value retrieval task requiring collating information across multiple data sources is proposed, which tests the ability of an agent to collate information from multiple data sources.
Conversational agents
A good agent should satisfy two aspects:
- Consistency -> conversation should be coherent
- Engagement -> referencing prior conversations makes dialogue more natural and engaging
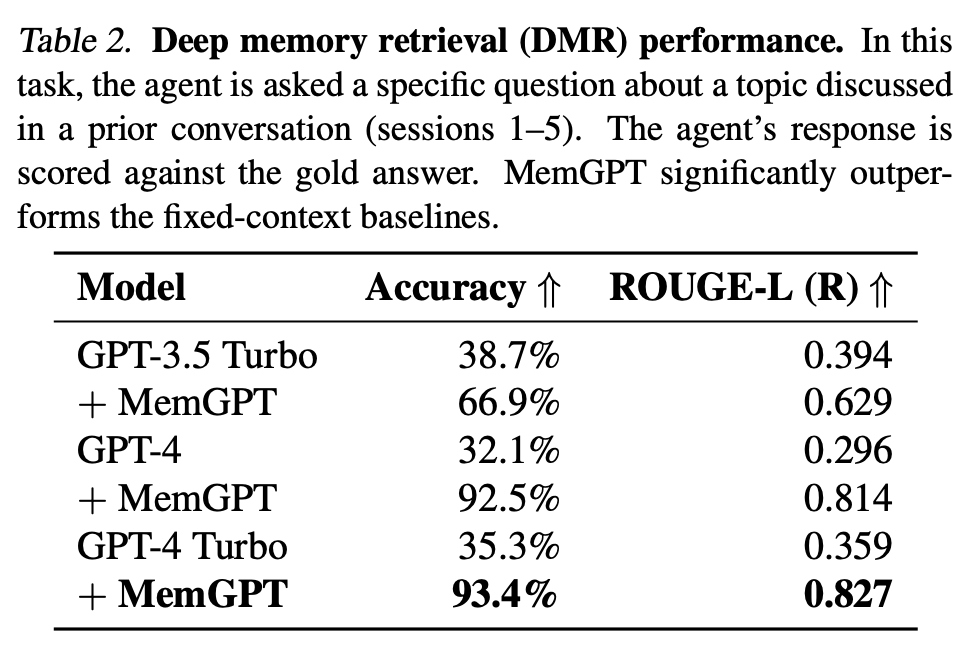
To test consistency, the deep memory retrieval (DMR) task is introduced. The conversational agent is asked a question by the user that explicitly refers back to a prior conversation and has a very narrow expected answer range.
To evaluate the answer, ROUGE-L scores and an LLM judge were used. Both the baselines and MemGPT provided more verbose answers compared to gold results, but MemGPT was way more accurate (see Table below), thanks to the recall memory.
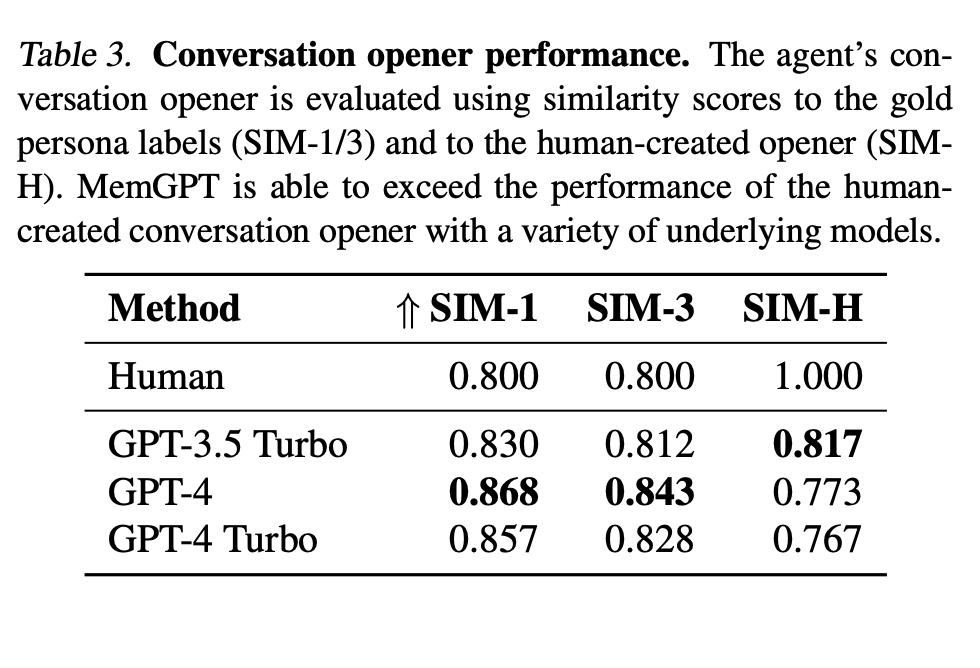
The conversation opener task was designed to measure the ability to provide engaging messages. The authors compared the generated opener to the gold personas: an engaging conversation opener should draw from one (or several) of the data points contained in the persona, which in the dataset effectively summarize the knowledge accumulated throughout all prior sessions.
MemGPT tends to craft openers that are both more verbose and cover more aspects of the persona information than the human baseline (check Table below).
Document analysis
For this task, MemGPT was benchmarked on fixed-context baselines on the retriever-reader document QA task from Liu et al. (2023a). The reader accuracy is evaluated as the number of retrieved documents K increases.
The same retrieval system was used for both the baseline and MemGPT and it consists in using similarity search on OpenAI’s text-embedding-ada-002 embeddings to get the top-k documents. PostgreSQL with its pgvector extension is used for the archival memory storage. An HNSW index is used to accelerate the retrieval.
The outputs are evaluated by an LLM judge.
MemGPT outperforms the fixed-context baseline because of its ability to perform multiple calls to the retriever, avoiding in this way the limitation of the context window.
Furthermore, baseline's performance are highly dependant on the retriever' capability of extracting the gold documents. In MemGPT this issue is way less present, but the paper also shows that MemGPT will often stop paging through retriever results before exhausting the retriever database.
An interesting test done by the authors consists into truncating the document segments returned by the retriever to fix the same number of documents into the available context. As expected, this caused a decrease in performance, as the chance of omitting relevant snippets increases, but this is more evident for GPT3.5 than GPT4 (so better function calling capabilities help in this scenario).
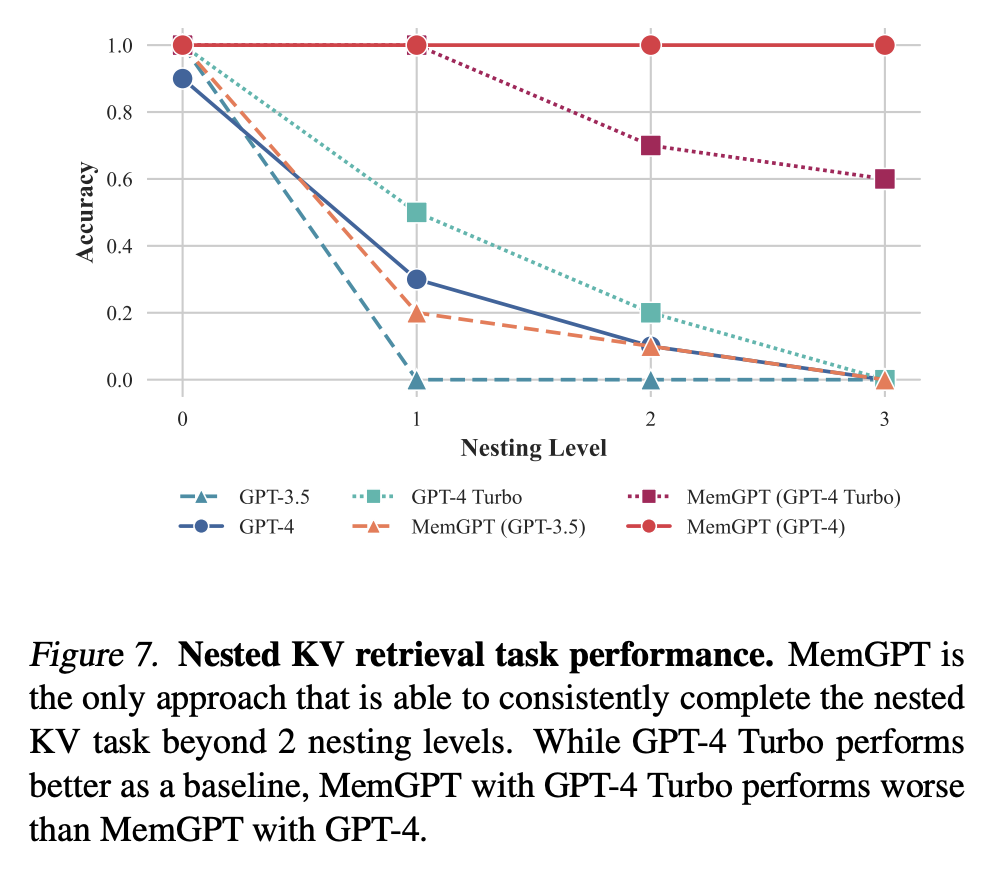
Nested Key-Value retrieval (KV)
This is a novel task, which aims to test the ability of the system to extract relevant data from multiple documents.
In the original KV task, given a dataset of keys and relative values (both are 128-bit UUID) and a key from this pool, the agent has to get the correspondent value.
In this new version, the values can be themselves keys, so the agent has to perform a multi-hoop operation to extract the value.
While GPT-3.5 and GPT-4 have good performance on the original KV tasks, both struggle in the nested KV task. MemGPT with GPT-4 on the other hand is unaffected with the number of nesting levels and is able to perform the nested lookup by accessing the key-value pairs stored in main context repeatedly via function queries (MemGPT with GPT3.5 and GPT4 Turbo are better than the baselines but still see a drop in performance after the 2 nesting level).
Ideas for future works
- Adding more concept from 'normal' OSes
- Different memory tier technologies like databases or caches
- Improving control flow and memory management policies
Issues
Safety issues related to agent:
References
Code
Tags
#llm #os #agents #nlp