Data2Vec - A General Framework For Self-supervised Learning In Speech, Vision And Language
Created: 2022-07-12 09:13
#paper
This paper proposes a unified framework for Self-Supervised Learning in three modalities: images, texts and speech. It achieves SOTA result in all three modalities.
Note: this work is not about multimodal learning, i.e during training just one of the modalities is passed as input. This does not mean that it can't be useful for multimodal learning.
The self-supervised part of the method takes inspiration from BYOL.
Note: Despite the unified learning regime, in the model modality-specific features extractors and masking strategies are used.
Main idea
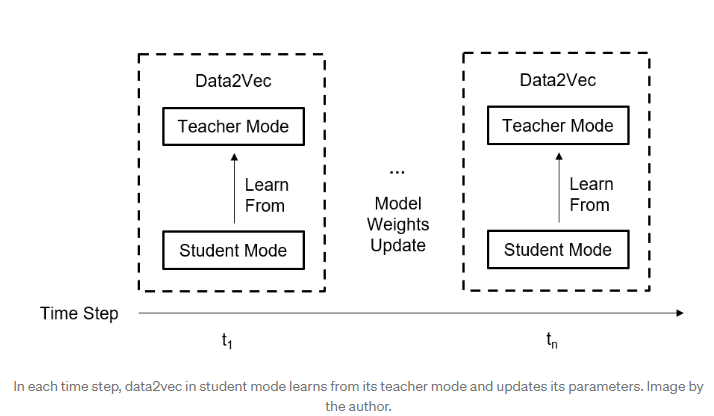
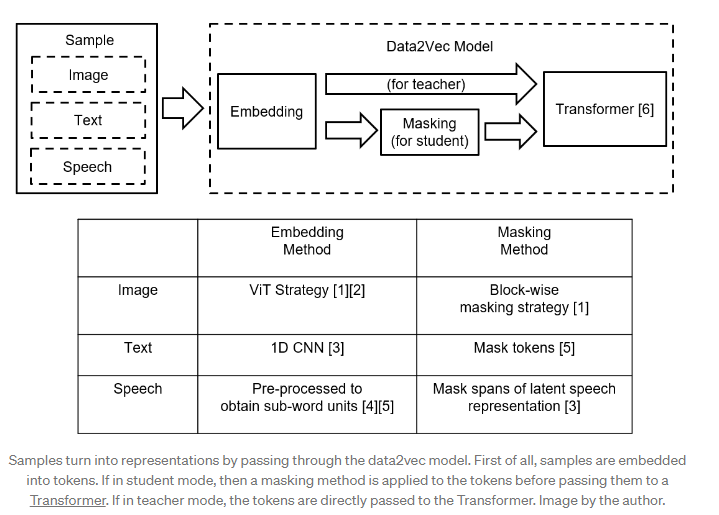
Data2Vec consists in two modes: the teacher mode and the student mode. In each timestamp, the student mode of data2vec will try to learn from the teacher mode and update the model parameters. In more details, the teacher generates representation from a given sample, while the student receives a masked version of the same representation. Learning consists in minimizing the distance between student's predictions and the representation created by the teacher.
{kind=link}
In deep
Data2Vec_architecture.PNG
The representations created by the teacher and the student are contextualized representations, i.e. they consider the timestamp and other information from the sample thanks to the self-attention mechanism.
{kind=link}
Teacher's parameters are updated using exponential moving average, that means that greater weights are given to more recent data points. Mathematical speaking, the parameters are updated in the following way: $\Delta \leftarrow \tau \Delta + (1 - \tau)\theta$, where $\theta$ is the student- mode model parameter, $\tau$ linearly increases over time to a target value $\tau_e$ and then stays constant.
The target is constructed by using the top K (closer to the output) blocks of the transformer: $y_t= \dfrac{1}{K} \sum_{l=L-K+1}^L \hat a_t^l$, where L is the total blocks in the network, $a_t^l$ is the output of block l at timestamp t and $\hat a_t^l$ is obtained by a normalization from $a_t^l$.
The objective funtion is:
$L(y_t,f_t(x))=
\begin{equation}
\begin{cases}
\dfrac{1}{2}(y_t - f_t(x))^2 / \beta & |y_t − f_t(x)| ≤ \beta \\(|y_t - f_t(x)|-\dfrac{1}{2}\beta)) & otherwise
\end{cases},
\end{equation},
$ with $y_t$ as target, $f_t(x)$ as prediction, $\beta$ parameter that controls the tansition from a squared loss to an $L_1$ loss ($L_1$ is used to make the loss less sensitive to outliers when the gap is large).
In a word, the teacher and the student have a dynamic behavior: student’s parameters are updates by optimizing the objective function, while the teacher’s parameters are updated by calculating the the EMA.
For the ablation study, the authors show that the use of top K blocks and FFN in the teacher mode improve results.