A Human-Inspired Reading Agent With GistMemory Of Very Long Contexts
Created: 2024-06-10 17:04
#paper
Main idea
The paper proposes an LLM agent system that handles long content inspired by the human approach -> people form two types of memory representations about a past event – verbatim and gist memories. Gist memories, often episodic, are fuzzy memories of past events, whereas verbatim memories contain details of past events. People prefer to reason with gists rather than with verbatim memories.
In deep
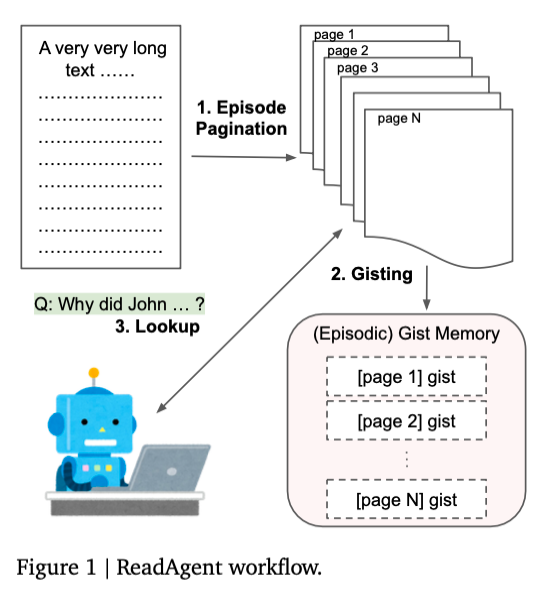
ReadAgent, a straightforward implementation, can be constructed entirely by prompting a pre-trained language model. As shown in the figure above, it operates in three main stages:
Episode Pagination: The language model determines suitable pause points while reading continuous text. The content between these pauses forms an episode, referred to as a page in this context.
Memory Gisting: The language model condenses each page into a shorter summary (gist) and links it to relevant context, such as the page number. This creates the episodic gist memory.
Interactive Look-Up: Given a task and the complete set of gists, the language model decides which page(s) to reference. It then combines the gists with the original page content to solve the task.
A Gist memory is an ordered collection of gists of chunks of text from the original long context. To build a gist memory the needed steps are the following:
- Episode Pagination: at each step, the LLM is provided with some text that starts from the previous pause point and ends after max_words limit. The LLM is asked to provide a natural point to pause in the text and that portion is defined as episode. In the text are present some suggested pause points between paragraphs, after min_words threshold, so the model has to make a multiple choice question;
- Memory Gisting: for each page, the LLM is prompted to shorten the content into a gist. Before the gist a tag is added (e.g. “⟨Page 2⟩\n{GIST CONTENT}”) to contextualize it and then all the gists are concatenated into a gist memory;
- Interactive Look-Up: ReadAgent is supposed to look up relevant details in the original text, in addition to using its gist memory. Two approaches were tried:
- ReadAgent-P: it consists in looking all pages at once in parallel. The maximum amount of pages to look up is given and the LLM is instructed to use as few pages as possible. The gists are replaced by the raw pages and the LLM is prompted again to solve the task with the updated memory.
- ReadAgent-S: it sequentially looks up one page at the time. The model gets to see the previously expanded pages before deciding which page to expand. The model access more information in this approach, so it should perform better (but it is more expensive).
Computational cost
The pagination algorithm splits the document into chunks of at most max_words, and then guarantees that at least min_words are consumed at each step. Thus, the ratio gives an upper bound on how many times the word length of the document the LLM must process using our algorithm.
Experiments
Three long-context question-answering challenges were used for evaluation: QuALITY, NarrativeQA and QMSum.
As raters, two LLM-based scores are defined:
- LLM-Rating-1 (LR-1): which counts the percentage of exact matches over all examples;
- LLM-Rating-2 (LR-2): which counts the percentage of exact and partial matches.
For some datasets ROUGE is also used.
For RAG baselines the techniques used were:
- Okapi BM25,
- neural retrieval based on Gemini API embedding model
Limits
The proposed approach is well-suited to densely-correlated long- document pieces, such as a series of books or a conversation history, but the database cannot scale arbitrarily, since the size of the gist memory is limited by the LLM’s context length, and the gist memory’s length correlates with the size of the database. In contrast, conventional retrieval approaches can handle larger databases than the approach.
References
Tags
#llm #agents