Contrastive Loss
Created: 2022-07-07 11:40
#note
Contrastive loss has been used recently in a number of papers showing state of the art results with unsupervised learning.
It is used when we need to compare the outputs produced from two different inputs (e.g. like in Siamese models).
Contrastive loss takes the output of the network for a positive example and calculates its distance to an example of the same class and contrasts that with the distance to negative examples. Said another way, the loss is low if positive samples are encoded to similar (closer) representations and negative examples are encoded to different (farther) representations. This is accomplished by taking the cosine distances of the vectors and treating the resulting distances as prediction probabilities from a typical categorization network. The big idea is that you can treat the distance of the positive example and the distances of the negative examples as output probabilities and use cross entropy loss.
contrastive_loss.PNG
Contrastive loss looks suspiciously like the softmax function. That’s because it is, with the addition of the vector similarity and a temperature normalization factor. The other difference is that values in the denominator are the cosign distance from the positive example to the negative samples.
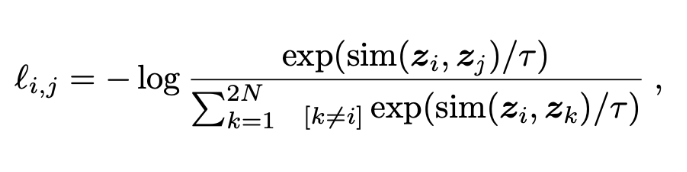{kind=link}