CLIP - Contrastive Language-Image Pre-Training
Created: 2022-07-01 10:02
#paper
Main idea
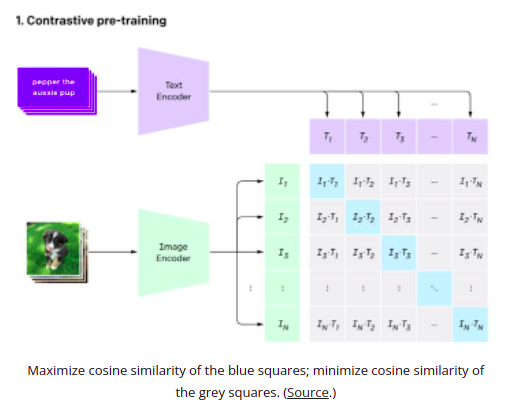
CLIP is a multimodal model released by OpenAI. It works very well in Zero-shot learning tasks.
A CLIP model consists of two encoders, one for texts and the other for images, that map images and texts to the same mathematical space. CLIP is then trained to predict how likely the image corresponds to the text using contrastive pre-training.