Classification Of Goods Using Text Descriptions With Sentences Retrieval
Created: 2023-10-26 08:59
#paper
Main idea
The paper proposes a deep learning model, developed in collaboration with Korea Customs Service, for the classification of traded goods using their text descriptions to assist in determining the Harmonized System (HS) codes, which are crucial for tariff rates. The model, based on KoELECTRA, was evaluated on 129,084 past cases and achieved a top-3 accuracy of 95.5% in classifying 265 subheadings, suggesting that such algorithms could significantly reduce the time and effort required by customs officers for HS code classification tasks.
Note: past examples are the primary determinant of the AI model’s decision, different from human experts who make their decision by rules and manuals. Since HS code and its manual undergo revision every five years, previous cases cannot always be good references for recent ones.
Dataset
The datasets used for the paper are from the customs law information portal (CLIP) from Korea Customs Service. The authors focused on chapter 85 since it was the one with more classification requests (17.1% as of 2020). 129.084 cases are included in the dataset.
Method
The proposed framework takes item description as an input, and the final goal is to predict the subheading (HS6) of a given item by referring to the HS manual. It also provides intermediate outputs for candidate headings and subheadings, prior cases, and key sentences from the HS manual.
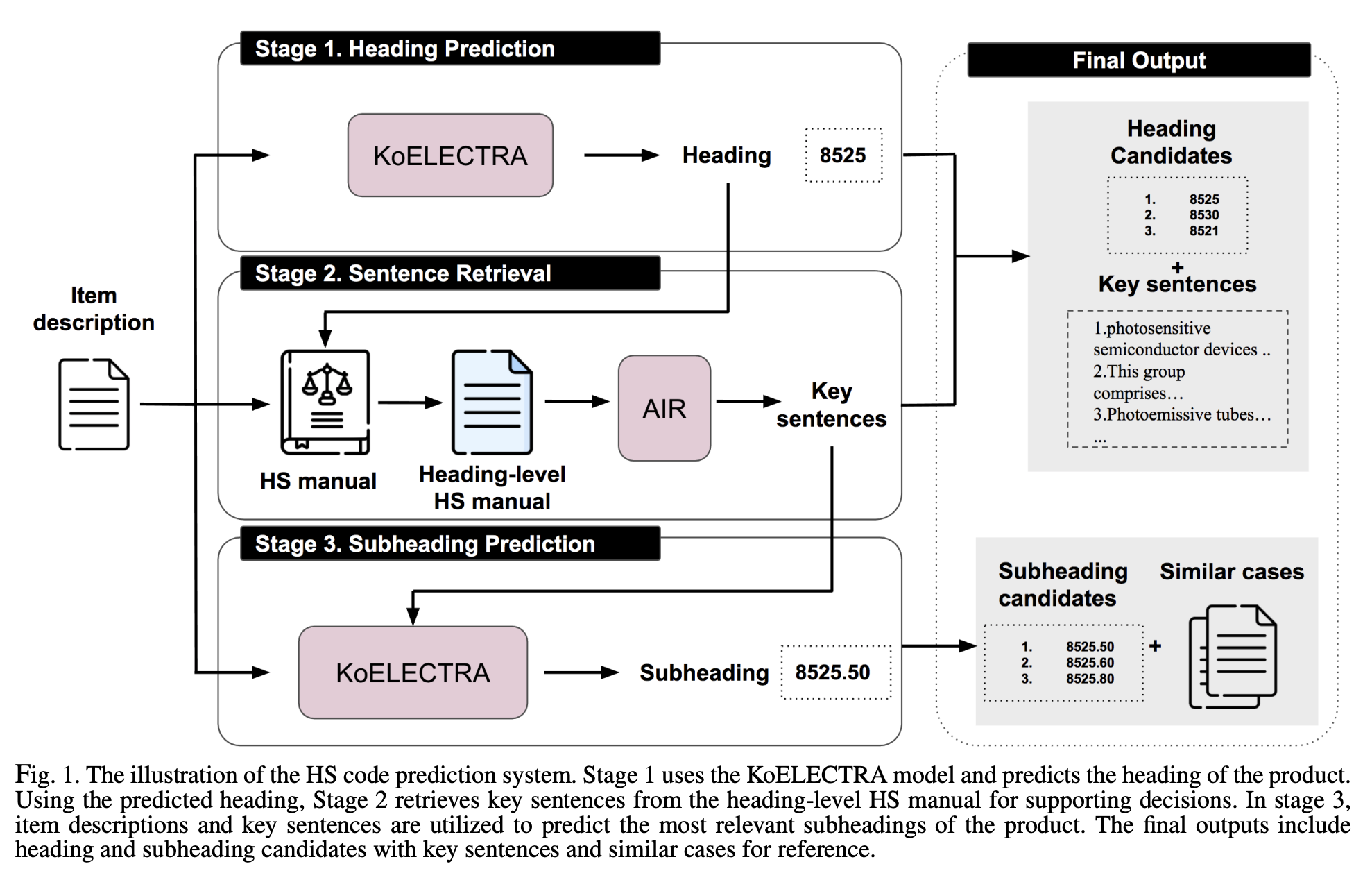
There are three stages:
- Heading prediction: the item description os translated into Korean and embedded in $R^d$. The item embedding goes through the classification head and a categorical cross-entropy loss is used;
- Sentence Retrieval: the name if the method used here is Alignment Information Retrieval (AIR), which consists in predicting the heading and then extracting key sentences from the HS manual to justify this decision. Key sentences are iteratively retrieved by calculating the similarity score between the item description xi and the heading-level HS manual M. The process terminates when retrieved sentences cover all keywords from input descriptions from M or no new keywords are discovered from M. The similarity measure is based on cosine similarity;
- Subheading prediction: using key sentences and item description, the model predicts the subheading candidates and retrieve prior cases that belong to each subheading in a similar way to what was done in step 1.
References
Tags
#hs #ml #sentenceretrieval