Adversarial Machine Learning - A Taxonomy And Terminology Of Attacks And Mitigations
Created: 2024-01-26 14:14
#paper
Discussed topics
This is the NIST Trustworthy and Responsible AI report which aims to develop a taxonomy of concepts and defines terminology in the field of adversarial machine learning (AML).
It was built on surveying AML literature and tries to cover key types of ML methods and lifecycle stages of attacks as well as mitigating techniques and consequences of attacks.
In this summary I will focus on Section 3, the one about GenAI-based applications.
Attack classification
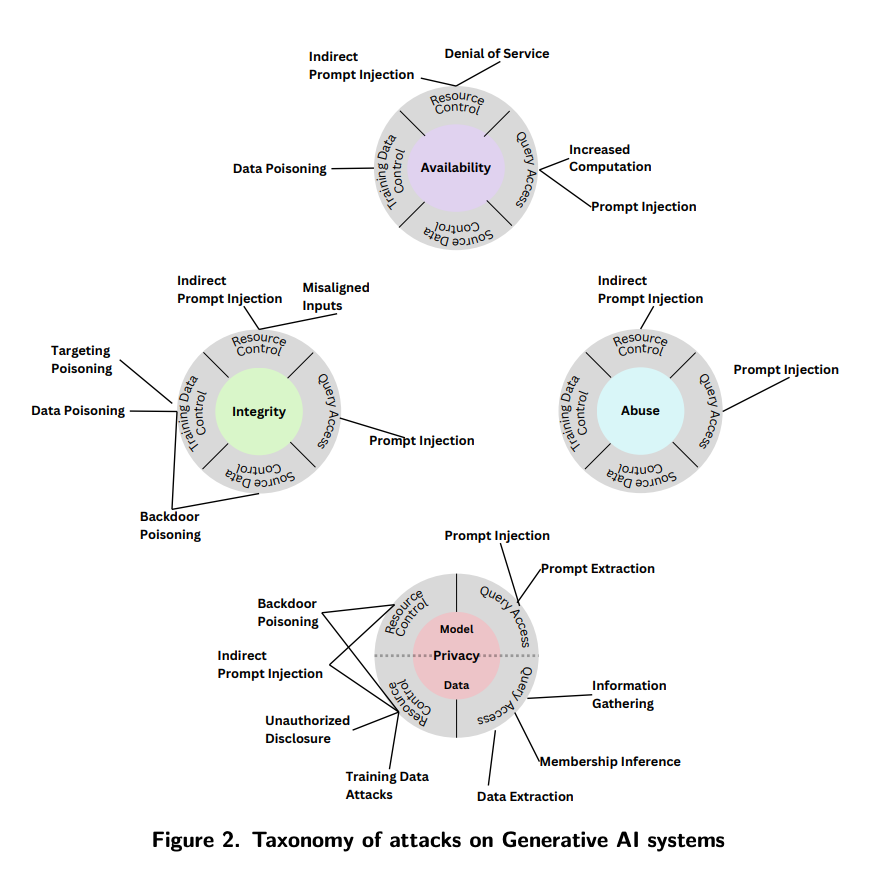 Training-time attacks: researchers have demonstrated that an attacker can induce targeted failures in models by arbitrarily poisoning only 0.001% of uncurated web-scale training datasets (e.g. by purchasing a small fraction of expired domains from known data sources) -> poisoning attacks
Training-time attacks: researchers have demonstrated that an attacker can induce targeted failures in models by arbitrarily poisoning only 0.001% of uncurated web-scale training datasets (e.g. by purchasing a small fraction of expired domains from known data sources) -> poisoning attacks
Inference-time attacks: decades-old SQL injection attacks have been proved to be effective with Large Language Models (LLMs) and RAG applications. Practises that are common and relative drawbacks:
- Alignment via model instructions: system prompt are used to steer the model's answer according to the application-specific use cases. An attacker can use a prompt extraction attack to steal these system instructions and then use a jailbreak to override the alignment and other safeguards.
- in RAG scenarios, indirect prompt injection attacks (i.e. modify the context using outside sources of information that are ingested by the system, even if not directly by the user) can be used.
Attacker goals and objectives
- Abuse violations: GenAI models can be used to promote hate speech or discrimination, malicious code, or in general offensive content
- Availability breakdown: attacker attempts to break down the performance of the model at deployment time. It can happen in several ways: via data poisoning, via model poisoning (i.e. attacker controls the model parameters), or as energy-latency attacks via query access.
- Integrity violations: it targets the integrity of an ML model's output, resulting in incorrect predictions performed by an model.Evasion attacks require the modification of testing samples to create adversarial examples that are misclassified by the model to a different class, while remaining stealthy and imperceptible to humans. Possible attacks are targeted poisoning attacks, backdoor poisoning attacks, model poisoning.
- Privacy compromise: attackers could be interested in learning information about the training data (data privacy attacks) or the ML model (model privacy attack). In more details, possible attacks regard: data reconstruction (inferring content or features of training data), membership-inference attacks (inferring the presence of data in the training set), data extraction (ability to extract training data from generative models), and property inference (inferring properties about the training data distribution). MODEL EXTRACTION is a model privacy attack in which attackers aim to extract information about the model.
Attacker capabilities
- Training data control: the attacker can take control of the training data by inserting or modifying training samples. This is used in data poisoning attacks.
- Query access: many GenAI models and applications are deployed as cloud-hosted services, so user submit a query and receive an output without having access to the application directly. The attacker's purpose could be to elicit a specific behavior from the model (prompt injection, prompt extraction).
- Source code control: the attacker could modify open source models with malicious code.
- Resource control: attacker could modify resources that will be ingested by the GenAI model at runtime (indirect prompt injection).
Attacks
AI supply chain attacks: they are related to they way (and sources) most GenAI project are built, i.e. many time open-source models or data are the base for these projects. Many vulnerabilities have been found in libraries like TensorFlow or OpenCV.
Some mitigations could be include the usage of safe model persistence formats, like safetensors or cryptographic hashes to verify download datasets.
Direct prompt injection: when attacker inject text to alter the behavior of the LLM. There are several techniques falling in this category:
- Gradient-based attacks: based on the usage of optimization techniques to generate adversarial examples, i.e. the adversary is allowed to inspect the entirety of the ML model and compute gradients relative to the model’s loss function.
- Manual methods: these techniques exploit certain linguistic manipulations to trick the model. There are two classes of possible attacks:
- Competing objectives, i.e. usage of additional instructions that compete with the instructions provided by the authors. Some attacks include: prefix injection (condition the model to begin its input in a predetermined manner makes it easier to influence subsequent generation), refusal suppression (additional instructions to avoid the generation of negative responses), style injection (influencing the style of the generation can lower the accuracy), role-play ("Do Anything Now" or "Always Intelligent and Machiavellian" attacks guide the model to adopt specific behavioral patterns that conflict with the original intent);
- Mismatch generalization, aims to position the input out of the distribution from the model's standard training data. Some attacks include: special encoding (e.g. use base64 to alter the representation of input data), character transformation (manipulating the input text with ciphers like Morse code or ROT13 can confuse the model), word transformation (break down sensitive words into substrings by using synonym swapping or Pig Latin for example), prompt-level obfuscation (introducing obfuscation with, for example, translations can create scenarios where the safety mechanisms are less effective)
- Automated model-based red teaming: it uses three models, an attacker, a target, and a judge. If an attacker can use a judge as classifier of harmful outputs, it may use a reward function to train generative models to generate jailbreaks of another generative model.
Data Extraction: GenAI models can simply be asked to repeat private information that exists in the context/training data as part of the conversation. Generally the more the attacker knows, the more they can extract. Other attacks could be related to Prompt and context stealing, i.e. violate intellectual property of system prompts and/or context provided by RAG applications.
Availability Violations
Model availability violations are a disruption in service that can be caused by an attacker prompting a model with maliciously crafted inputs that cause increased computation or by overwhelming the system with a number of inputs that causes a denial of service to users.
Techniques:
- Time-consuming background tasks: the attacker asks to perform a time-consuming task before answering the request (e.g. looping request);
- Muting: by requesting something that starts with <|endoftext|>, the model could not be able to continue the generation of the answer;
- Inhibiting capabilities: input includes instruction to not use certain functionalities, like API calls, to limit the capabilities of the system;
- Disrupting input or output: In this attack, an indirect prompt injection instructs the model to replace characters in retrieved text with homoglyph equivalents, disrupting calls to APIs that depend on the text. Alternatively, the prompt can instruct the model to corrupt the results of a query to result in a useless retrieval or summary.
Integrity violations
Integrity violations are threats that cause GenAI systems to become untrustworthy.
Techniques:
- Manipulation: The manipulation attack instructs the model to provide wrong answers and causes the model’s answer to make claims that contradict the cited sources. Examples are related to wrong summaries or propagation of disinformation.
Privacy Compromises
Indirect prompt injections introduce a host of new privacy compromises and concerns. They are used to gather user private data for example.
Techniques:
- Human-in-the-loop indirect prompting: read operations are exploited to send information to the attacker;
- Interacting in chat sessions: The model persuades a user to follow a URL into which the attacker inserts the user’s name;
- Invisible markdown image: A prompt injection is performed on a chatbot by modifying the chatbot answer with an invisible single-pixel markdown image that withdraws the user’s chat data to a malicious third party.
Abuse violations
This broadly refers to when an attacker repurposes a system’s intended use to achieve their own objectives by way of indirect prompt injection. Examples as frauds, spread of malware, and manipulation (users can trust these systems more than sources on the web).
Techniques:
- Phishing, LLMs can create and spread scams;
- Masquerading, as LLMs can pretend to be an official request from a service provider or provide fraudulent websites in the output;
- Spreading injections, as a model can use data generated by other fraudulent models;
- Spreading malware, as in Phishing, LLMs can provide links to download harmful content;
- Historical distortion, models can be prompt to choose disinformative content;
- Marginally related context prompting, as models can be steered to generate oriented output (i.e. biased content).
Mitigations
Some measure of protections have been propose (they cannot cover all cases). Some are:
- Alignment during training (or fine-tuning);
- Prompt instructions (aka system prompts);
- Formatting of the input;
- Detection techniques (for malevolent input or jailbroke output);
- RLHF (but models tuned to follow instructions can sometimes be tricked more easily);
- LLM-based moderator to detect attacks;
- Interpretability-based solutions -> outlier detection of prediction trajectories.
References
Tags
#survey #ml #genai #AML #cybersecurity