Activation Functions
Created: 2022-12-02 16:21
#note
Activation functions "decide" if the neuron should fire or not. They are fundamental to the computation of gradients during Back Propagation, making them essential to neural network training.
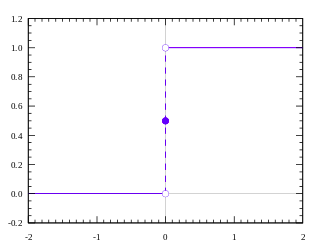
Step function
It is just a threshold based activation function, it does not give intermediate values. It is not really good for non binary activations.
Linear function
The activation is proportional to the input.
Problem: the derivative is constant, i.e. the gradient has no relationship with the input. Also, having just linear activation functions means that the last layer is just a linear function of the first layer. This means that we could replace all the layers with a single layer.
Output values are in the range (-inf; inf).
Sigmoid function
It is a smoother version of the step function. $A = \frac{1}{1+e^{-x}}$ → It is nonlinear in nature and works with non-binary activations. Also, it has the tendency to bring values to either end of the curve. Values are included in the range (0,1).
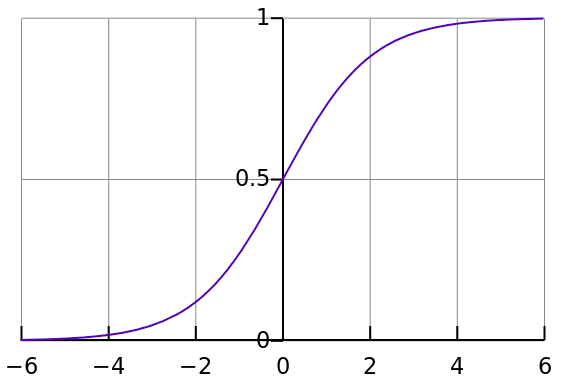
Problem: vanishing gradient caused by values that falls at the "near-horizontal" part of the curve.
Tanh function
It is a scaled sigmoid function → $f(x)=tanh(x)=\frac{2}{1+e^{-2x}}-1$, i.e. $tanh(x)=2sigmoid(2x)-1$.
It is really similar to sigmoid, it just works in the range (-1;1) and it causes a stronger gradient.
ReLu
$A(x)=max(0,x)$.
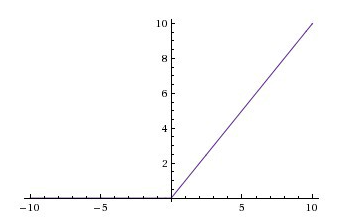
It gives an output x if x is positive and 0 otherwise.
Even if it seems linear, ReLu is non-linear in nature.
A good aspect of ReLu, compared to sigmoid and tanh, is that it does not activate all the neurons, i.e. the network is lighter.
Problems:
- it is not bounded, so it can blow up the activation;
- gradient can go towards 0 because of the horizontal line → dying ReLu problem (this can be solved by Leaky ReLu)